Chapter 9: Structures
What's in Chapter 9?
Structure Declarations
Accessing elements of a structure
Initialization of structure data
Using pointers to access structures
Passing structures as parameters to functions
Example of MC68HC812A4 extended addressing
Example of a Linear Linked List
Example of a Huffman Code
A structure is a collection of variables that share a single name. In an array, each element has the same format. With structures we specify the types and names of each of the elements or members of the structure. The individual members of a structure are referenced by their subname. Therefore, to access data stored in a structure, we must give both the name of the collection and the name of the element. Structures are one of the most powerful features of the C language. In the same way that functions allow us to extend the C language to include new operations, structures provide a mechanism for extending the data types. With structures we can add new data types derived from an aggregate of existing types.
Like other elements of C programming, the structure must be declared before it can be used. The declaration specifies the tagname of the structure and the names and types of the individual members. The following example has three members: one 16-bit integer and two character pointers
struct theport{
int mode; // 0 for I/O, 1 for in only -1 for out only
unsigned char volatile *addr; // pointer to its address
unsigned char volatile *ddr;}; // pointer to its direction
reg
The above declaration does not create any variables or allocate any space. Therefore to use a structure we must define a global or local variable of this type. The tagname (theport) along with the keyword struct can be used to define variables of this new data type:
struct theport PortA,PortB,PortC;
The above line defines the three variables and allocates 6 bytes for each of variable. If you knew you needed just three copies of structures of this type, you could have defined them as
struct theport{
int mode;
unsigned char volatile *addr;
unsigned char volatile *ddr;}PortA,PortB,PortC;
Definitions like the above are hard to extend, so to improve code reuse we can use typedef to actually create a new data type (called port in the example below) that behaves syntactically like char int short etc.
struct theport{
int mode; // 0 for I/O, 1 for in only -1 for out only
unsigned char volatile *addr; // address
unsigned char volatile *ddr;}; // direction reg
typedef struct theport port;
port PortA,PortB,PortC;
Once we have used typedef to create port, we don't need access to the name theport anymore. Consequently, some programmers use to following short-cut:
typedef struct {
int mode; // 0 for I/O, 1 for in only -1 for out only
unsigned char volatile *addr; // address
unsigned char volatile *ddr;}port; // direction reg
port PortA,PortB,PortC;
Similarly, I have also seen the following approach to creating structures that uses the same structure name as the typedef name:
struct port{
int mode; // 0 for I/O, 1 for in only -1 for out only
unsigned char volatile *addr; // address
unsigned char volatile *ddr;}; // direction reg
typedef struct port port;
port PortA,PortB,PortC;
Imagecraft and Metrowerks support all of the above methods of declaring and defining structures.
Accessing Members of a Structure
We need to specify both the structure name (name of the variable) and the member name when accessing information stored in a structure. The following examples show accesses to individual members:
PortB.mode=-1; // 6811 Port B is output only
PortB.addr=(unsigned char volatile *)(0x1004);
PortC.mode=0; // 6811 Port C is input and output
PortC.addr=(unsigned char volatile *)(0x1003);
PortC.ddr=(unsigned char volatile *)(0x1007);
(*PortC.ddr)=0; //
specify PortC as inputs
(*PortB.addr)=(*PortC.addr); // copy from PortC to PortB
The syntax can get a little complicated when a member of a structure is another structure as illustrated in the next example:
struct theline{
int x1,y1; // starting point
int x2,y2; // starting point
char color;}; // color
typedef struct theline line;
struct thepath{
line L1,L2; // two lines
char direction;};
typedef struct thepath path;
path p; // global
void Setp(void){ line myLine; path q;
p.L1.x1=5; // black line from 5,6 to 10,12
p.L1.y1=6;
p.L1.x2=10;
p.L1.y2=12;
p.L1.color=255;
p.L2={5,6,10,12,255}; // black line from 5,6 to 10,12
p.direction=-1;
myLine=p.L1;
q={{0,0,5,6,128},{5,6,-10,6,128},1};
q=p;
};
The local variable declaration line myLine; will allocate 7 bytes on the stack while path q; will allocate 15 bytes on the stack. In actuality most C compilers in an attempt to maintain addresses as even numbers will actually allocate 8 and 16 bytes respectively. In particular, the 6812 executes faster out of external memory if 16 bit accesses occur on even addresses. For example, a 16-bit data access to an external odd address requires two bus cycles, while a 16-bit data access to an external even address requires only one bus cycle. There is no particular odd-address speed penalty for any 6811 address or for 6812 internal addresses (internal RAM or EEPROM). Notice that the expression p.L1.x1 is of the type int, the term p.L1 has the type line, while just p has the type path. The expression q=p; will copy the entire 15 bytes that constitute the structure from p to q.
Just like any variable, we can specify the initial value of a structure at the time of its definition.
path thePath={{0,0,5,6,128},{5,6,-10,6,128},1};
line thePath={0,0,5,6,128};
port PortE={1,
(unsigned char volatile *)(0x100A),
(unsigned char volatile *)(0)};
If we leave part of the initialization blank it is filled with zeros.
path thePath={{0,0,5,6,128},};
line thePath={5,6,10,12,};
port PortE={1, (unsigned char volatile *)(0x100A),};
To place a structure in ROM, we define it as a global constant. In the following example the structure fsm[3] will be allocated and initialized in ROM-space. The linked-structure finite syatem machine is a good example of a ROM-based structure. For more information about finite state machines see Chapter 2 of the book Embedded Microcomputer Systems: Real Time Interfacing by Jonathan Valvano published by Brooks-Cole.
const struct State{
unsigned char Out; /* Output to Port H */
unsigned short Wait; /* Time (E cycles) to wait */
unsigned char AndMask[4];
unsigned char EquMask[4];
const struct State *Next[4];}; /* Next states */
typedef const struct State StateType;
typedef StateType * StatePtr;
#define stop &fsm[0]
#define turn &fsm[1]
#define bend &fsm[2]
StateType fsm[3]={
{0x34, 2000, // stop 1 ms
{0xFF, 0xF0, 0x27, 0x00},
{0x51, 0xA0, 0x07, 0x00},
{turn, stop, turn, bend}},
{0xB3,5000, // turn 2.5 ms
{0x80, 0xF0, 0x00, 0x00},
{0x00, 0x90, 0x00, 0x00},
{bend, stop, turn, turn}},
{0x75,4000, // bend 2 ms
{0xFF, 0x0F, 0x01, 0x00},
{0x12, 0x05, 0x00, 0x00},
{stop, stop, turn, stop}}};
Using pointers to access structures
Just like other variables we can use pointers to access information stored in a structure. The syntax is illustrated in the following examples:
void Setp(void){ path *ppt;
ppt=&p; // pointer to an existing global variable
ppt->L1.x1=5; // black line from 5,6 to 10,12
ppt->L1.y1=6;
ppt->L1.x2=10;
ppt->L1.y2=12;
ppt->L1.color=255;
ppt->L2={5,6,10,12,255}; // black line from 5,6 to 10,12
ppt->direction=-1;
(*ppt).direction=-1;
};
Notice that the syntax ppt->direction is equivalent to (*ppt).direction. The parentheses in this access are required, because along with () and [], the operators . and -> have the highest precedence and associate from left to right. Therefore *ppt.direction would be a syntax error because ppt.direction can not be evaluated.
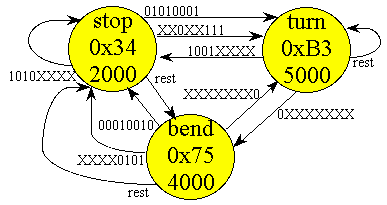
As an another example of pointer access consider the finite state machine controller for the fsm[3] structure shown above. The state machine is illustrated in Figure 9-1, and the program shown in Listing 9-4. There is an example in Chapter 10 that extends this machine to implement function pointers.
void control(void){ StatePtr Pt;
unsigned char Input; unsigned short startTime; unsigned int i;
TSCR1 |= 0x80; // TEN(enable)
TSCR2 = 0x01; // timer/2 (500ns)
DDRA = 0xFF; // PortA bits 7-0 are outputs
DDRB = 0x00; // PortB bits 7-0 are inputs
Pt = stop; // Initial State
while(1){
PORTA = Pt->Out; // 1) output
startTime =
TCNT; // Time (500 ns
each) to wait
while((TCNT-startTime)<+Pt->Wait); // 2) wait
Input =
PORTB;
// 3) input
for(i=0;i<4;i++)
if((Input&Pt->AndMask[i])==Pt->EquMask[i]){
Pt =
Pt->Next[i]; // 4) next depends on input
i=4; }}};
Passing Structures to Functions
Like any other data type, we can pass structures as parameters to functions. Because most structures occupy a large number of bytes, it makes more sense to pass the structure by reference rather than by value. In the following "call by value" example, the entire 6-byte structure is copied on the stack when the function is called.
unsigned char Input(port thePort){
return (*thePort.addr);}
When we use "call by reference", a pointer to the structure is passed when the function is called.
typedef const struct {
int mode; // 0 for I/O, 1 for in only -1 for out only
unsigned char volatile *addr; // address
unsigned char volatile *ddr;}port; // direction reg
port PortJ={
0,
(unsigned char volatile *)(0x0028),
(unsigned char volatile *)(0x0029)};
int MakeOutput(port *ppt){
if(ppt->mode==1) return 0; // input only
if(ppt->mode==-1) return 1; // OK, output only
(*ppt->ddr)=0xff; // make output
return 1;}
int MakeInput(port *ppt){
if(ppt->mode==-1) return 0; // output only
if(ppt->mode==1) return 1; // OK, input only
(*ppt->ddr)=0x00; // make input
return 1;}
unsigned char Input(port *ppt){
return (*ppt->addr);}
void Output(port *ppt, unsigned char data){
(*ppt->addr)=data;
}
void main(void){ unsigned char MyData;
MakeInput(&PortJ);
MakeOutput(&PortJ);
Output(&PortJ,0);
MyData=Input(&PortJ);
}
Extended Address Data Page Interface to the MC68HC812A4
One of the unique features of the MC68HC812A4 is its ability to interface large RAM and ROM using the data page and program page memory respectively. Up to 1Meg bytes can be configured using the data page system. In this example, two 128K by 8 bit RAM chips are interfaced to the 6812 using 18 address pins (A17-A0). The 628128 is a 128K by 8 bit static RAM. When the paged memory is enabled Port G will contain address lines A21-A16 (although the data page system can only use up to A19). The built-in address decoder CSD must be used with the data page system. The details of this interface can be found in Chapter 9 of the book Embedded Microcomputer Systems: Real Time Interfacing by Jonathan Valvano published by Brooks Cole.
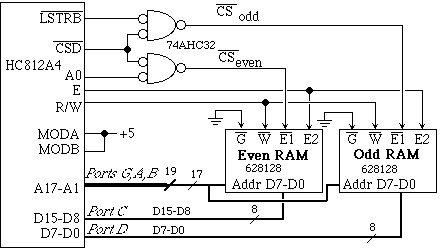
We divide the software into initialization and access. The initialization software performs the usual steps:
enable E, LSTRB, CSD, R/W outputs
clear bit 4 in the CSCTL1 to set up CSD for the $7000-$7FFF range
select 1 cycle stretch on CSD
To enable the data page system we must also
set bit 7 in WINDEF to enable the Data Page Window
set bits 1,0 in MXAR to enable memory expansion pins A17-A16
void RAMinit(void){
MODE=0x7B //
special expanded wide mode
PEAR=0x2C; // enable E, R/W, LSTRB
WINDEF=WINDEF|0x80; // enable DPAGE
MXAR=0x03; //
enable A17, A16 on Port G
CSCTL0=CSCTL0|0x10; // enable CSD
CSCTL1=CSCTL1&0xEF; // CSD $7000 to $7FFF
CSSTR0=(CSSTR0&0xFC)|0x01;} // 1 cycle stretch on CSD
Let A17-A0 be the desired 256K RAM location. To access that location requires two steps
set the most significant addresses A17-A12 into DPAGE register
access $7000 to $7FFF, with the least significant addresses A11-A0
struct addr20
{ unsigned char msb; // bits 19-12, only 17-12 used here
unsigned int lsw; // bits 11-0
};
typedef struct addr20 addr20Type;
char ReadMem(addr20Type addr){ char *pt;
DPAGE=addr.msb; // set addr bits 19-12, only 17-12 used
pt=(char *)(0x7000+addr.lsw); // set address bits 11-0
return *pt;} // read access
void WriteMem(addr20Type addr, char data){ char *pt;
DPAGE=addr.msb; // set addr bits 19-12, only 17-12 used
pt=(char *)(0x7000+addr.lsw); // set address bits 11-0
*pt=data;} // write access
When MXAR is active, the MC68HC812A4 will convert all 16 addresses to the extended 22 bit addresses. When an access is outside the range of any active page window (EPAGE, DPAGE or PPAGE), the upper 6 bits are 1. In the following table it is assumed that only the DPAGE is active, the DPAGE register contains DP7-DP0, and MXAR is 0x3F (activating all 22 address bits)
| internal | A21 | A20 | A19 | A18 | A17 | A16 | A15 | A14 | A13 | A12 | A11-A0 |
| $0xxx | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | xxx |
| $1xxx | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | xxx |
| $2xxx | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 0 | xxx |
| $3xxx | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | xxx |
| $4xxx | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | xxx |
| $5xxx | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | xxx |
| $6xxx | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | xxx |
| $7xxx | 1 | 1 | DP7 | DP6 | DP5 | DP4 | DP3 | DP2 | DP1 | DP0 | xxx |
From this table, we can see another trick when using paged memory. If we were to switch the initialization so that CSD activated on $0000-$7FFF (CSCTL1=CSCTL1|0x10;), then 7 4K pages would overlap the regular address range $0000 to $6FFF. In this particular system, there are 64 data pages, numbered $00 to $3F. Notice that page numbers $30 through $36 overlap with regular data space $0000 to $6FFF. If we avoid using data pages $30-$36, we would have 28K of regular RAM from $0000 to $6FFF plus 57 4K windows of data paged memory space.
One of the applications of structures involves linking elements together with pointers. A linear linked list is a simple 1-D data structure where the nodes are chained together one after another. Each node contains data and a link to the next node. The first node is pointed to by the HeadPt and the last node has a null-pointer in the next field. A node could be defined as
struct node{
unsigned short data; // 16 bit information
struct node *next; // pointer to the next
};
typedef struct node nodeType;
nodeType *HeadPt;

In order to store more data in the structure, we will first create a new node then link it into the list. The routine StoreData will return a true value if successful.
#include <STDLIB.H>;
int StoreData(unsigned short info){ nodeType *pt;
pt=malloc(sizeof(nodeType)); // create a new entry
if(pt){
pt->data=info; //
store data
pt->next=HeadPt; //
link into existing
HeadPt=pt;
return(1);
}
return(0); // out of memory
};
In order to search the list we start at the HeadPt, and stop when the pointer becomes null. The routine Search will return a pointer to the node if found, and it will return a null-pointer if the data is not found.
nodeType *Search(unsigned short info){ nodeType *pt;
pt=HeadPt;
while(pt){
if(pt->data==info)
return (pt);
pt=pt->next; // link to next
}
return(pt); // not found
};
To count the number of elements, we again start at the HeadPt, and stop when the pointer becomes null. The routine Count will return the number of elements in the list.
unsigned short Count(void){ nodeType *pt;
unsigned short cnt;
cnt=0;
pt=HeadPt;
while(pt){
cnt++;
pt=pt->next; // link to next
}
return(cnt);
};
If we wanted to maintain a sorted list, then we can insert new data at the proper place, in between data elements smaller and larger than the one we are inserting. In the following figure we are inserting the element 250 in between elements 200 and 300.
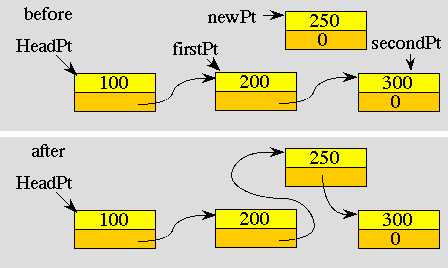
In case 1, the list is initially empty, and this new element is the first and only one. In case 2, the new element is inserted at the front of the list because it has the smallest data value. Case 3 is the general case depicted in the above figure. In this situation, the new element is placed in between firstPt and secondPt. In case 4, the new element is placed at the end of the list because it has the largest data value.
#include <STDLIB.H>;
int InsertData(unsigned short info){
nodeType *firstPt,*secondPt,*newPt;
newPt=malloc(sizeof(nodeType)); // create a new entry
if(newPt){
newPt->data=info; //
store data
if(HeadPt==0){ // case 1
newPt->next=HeadPt; // only element
HeadPt=newPt;
return(1);
}
if(info<=HeadPt->data){ // case 2
newPt->next=HeadPt; // first element in list
HeadPt=newPt;
return(1);
}
firstPt=HeadPt; // search from beginning
secondPt=HeadPt->next;
while(secondPt){
if(info<=secondPt->data){ // case 3
newPt->next=secondPt; // insert element here
firstPt->next=newPt;
return(1);
}
firstPt=secondPt; // search next
secondPt=secondPt->next;
}
newPt->next=secondPt; // case 4, insert at end
firstPt->next=newPt;
return(1);
}
return(0); // out of memory
};
The following function will search and remove a node from the linked list. Case 1 is the situation in which an attempt is made to remove an element from an empty list. The return value of zero signifies the attempt failed. In case 2, the first element is removed. In this situation the HeadPt must be updated to now point to the second element. It is possible the second element does not exist, because the list orginally had only one element. This is OK because in this situation HeadPt will be set to null signifying the list is now empty. Case 3 is the general situation in which the element at secondPt is removed. The element before, firstPt, is now linked to the element after. Case 4 is the situation where the element that was requested to be removed did not exist. In this case, the return value of zero signifies the request failed.
#include <STDLIB.H>;
int Remove(unsigned short info){
nodeType *firstPt,*secondPt;
if(HeadPt==0) // case 1
return(0); // empty list
firstPt=HeadPt;
secondPt=HeadPt->next;
if(info==HeadPt->data){ // case 2
HeadPt=secondPt; // remove first element in list
free(firstPt); // return unneeded memory to heap
return(1);
}
while(secondPt){
if(secondPt->data==info){ // case 3
firstPt->next=secondPt->next; // remove this one
free(secondPt); // return unneeded memory to heap
return(1);
}
firstPt=secondPt; // search next
secondPt=secondPt->next;
}
return(0); // case 4, not found
};
When information is stored or transmitted there is a fixed cost for each bit. Data compression and decompression provide a means to reduce this cost without loss of information. If the sending computer compresses a message before transmission and the receiving computer decompresses it at the destination, the effective bandwidth is increased. In particular, this example introduces a way to process bit streams using Huffman encoding and decoding. A typical application is illustrated by the following flow diagram.
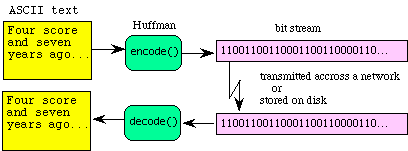
The Huffman code is similar to the Morse code in that they both use short patterns for letters that occur more frequently. In regular ASCII, all characters are encoded with the same number of bits (8). Conversely, with the Huffman code, we assign codes where the number of bits to encode each letter varies. In this way, we can use short codes for letter like "e s i a t o n" (that have a higher probability of occurrence) and long codes for seldom used consonants like "j q w z" (that have a lower probability of occurrence). To illustrate the encode-decode operations, consider the following Huffman code for the letters M,I,P,S. S is encoded as "0", I as "10", P as "110" and M as "111". We can store a Huffman code as a binary tree.
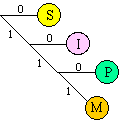
If "MISSISSIPPI" were to be stored in ASCII, it would require 10 bytes or 80 bits. With this simple Huffman code, the same string can be stored in 21 bits.

Of course, this Huffman code can only handle 4 letters, while the ASCII code has 128 possibilities, so it is not fair to claim we have an 80 to 21 bit savings. Nevertheless, for information that has a wide range of individual probabilities of occurrence, a Huffman code will be efficient. In the following implementation the functions BitPut() and BitGet() are called to save and recover binary data. The implementations of these two functions were presented back in Chapter 2.
const struct Node{
char Letter0; // ASCII code if binary 0
char Letter1; // ASCII code if binary 1
// Letter1 is NULL(0) if Link is pointer to another node
const struct Node *Link;}; // binary tree pointer
typedef const struct Node NodeType;
typedef NodeType * NodePtr;
// Huffman tree
NodeType twentysixth= {'Q','Z',0};
NodeType twentyfifth= {'X',0,&twentysixth};
NodeType twentyfourth={'G',0,&twentyfifth};
NodeType twentythird= {'J',0,&twentyfourth};
NodeType twentysecond={'W',0,&twentythird};
NodeType twentyfirst= {'V',0,&twentysecond};
NodeType twentyth= {'H',0,&twentyfirst};
NodeType ninteenth= {'F',0,&twentyth};
NodeType eighteenth= {'B',0,&ninteenth};
NodeType seventeenth= {'K',0,&eighteenth};
NodeType sixteenth= {'D',0,&seventeenth};
NodeType fifteenth= {'P',0,&sixteenth};
NodeType fourteenth= {'M',0,&fifteenth};
NodeType thirteenth= {'Y',0,&fourteenth};
NodeType twelfth= {'L',0,&thirteenth};
NodeType eleventh= {'U',0,&twelfth};
NodeType tenth= {'R',0,&eleventh};
NodeType ninth= {'C',0,&tenth};
NodeType eighth= {'O',0,&ninth};
NodeType seventh= {' ',0,&eighth};
NodeType sixth= {'N',0,&seventh};
NodeType fifth= {'I',0,&sixth};
NodeType fourth= {'S',0,&fifth};
NodeType third= {'T',0,&fourth};
NodeType second= {'A',0,&third};
NodeType root= {'E',0,&second};
//********encode***************
// convert ASCII string to Huffman bit sequence
// returns bit count if OK
// returns 0 if BitFifo Full
// returns 0xFFFF if illegal character
int encode(char *sPt){ // null-terminated ASCII string
int NotFound; char data;
int BitCount=0; // number of bits created
NodePtr hpt; // pointer into Huffman tree
while (data=(*sPt)){
sPt++; // next character
hpt=&root; // start search at root
NotFound=1; // changes to 0 when found
while(NotFound){
if ((hpt->Letter0)==data){
if(!BitPut(0))
return (0); // data structure full
BitCount++;
NotFound=0; }
else {
if(!BitPut(1))
return (0); // data structure full
BitCount++;
if ((hpt->Letter1)==data)
NotFound=0;
else { // doesn't match either Letter0 or Letter1
hpt=hpt->Link;
if (hpt==0) return (0xFFFF); // illegal, end of tree?
}
}
}
}
return BitCount;
}
//********decode***************
// convert Huffman bit sequence to ASCII
// will remove from the BitFifo until it is empty
// returns character count
int decode(char *sPt){ // null-terminated ASCII string
int CharCount=0; // number of ASCII characters created
int NotFound; unsigned int data;
NodePtr hpt; // pointer into Huffman tree
hpt=&root; // start search at root
while (BitGet(&data)){
if (data==0){
(*sPt)= (hpt->Letter0);
sPt++;
CharCount++;
hpt=&root;} // start over and search at root
else //data is 1
if((hpt->Link)==0){
(*sPt)= (hpt->Letter1);
sPt++;
CharCount++;
hpt=&root;} // start over and search at root
else { // doesn't match either Letter0 or Letter1
hpt=hpt->Link;
}
}
(*sPt)=0; // null terminated
return CharCount;
}
Go to Chapter 10 on Functions Return to Table of Contents