Sujay Sanghavi - Selected Projects and Related Papers
Navigation:
Robust high-dimensional inference
High-dimensional inference involves settings where the dimension of the ambient space far exceeds the amount of data or samples available. Statistically, this means that consistency is only achieved via the use of additional structural properties data might contain (e.g. sparsity, low-rank representations, Markov structure, etc.). Our work has pioneered methods that can leverage super-positions of structural characteristics, greatly expanding both the application domains and the robustness of high-dimensional inference methods.
Sparse and Low-Rank Matrix Decompositions (SIAM Journal of Optimization) investigates when a sparse matrix, and a low-rank matrix, can be individually recovered from their sum, using a convex optimization based algorithm. Our follow-up paper Low-rank Matrix Recovery from Errors and Erasures (Trans. on Info. Theory) provides the current best guarantees for this problem.
Both other groups and ours has found applications of sparse + low-rank modeling in latent variable modeling, graph clustering (see below), robust versions of PCA, etc. One example is our paper Learning the Dependence Graph of Time Series with Latent Factors (ICML 2012), which finds the dependence structure of stochastic differential equations with latent variables in high dimensions.
Our paper A Dirty Model for Multiple Sparse Regression (Trans. Info. Theory, NIPS 2010) provides a new algorithm for multiple sparse linear regression with partially shared sparsity; it outperforms all existing algorithms in sample complexity. The two structures super-posed are sparsity, and block-sparisty.
Another issue is robustness to outliers; the paper Robust PCA via Outlier Pursuit (Trans. Info. Theory, NIPS 2010) looks at this in the context of PCA. The arbitrary outliers manifest as a column-sparse addition to a ‘‘true" low-rank matrix; our algorithm learns both jointly from data. Standard SVD-based PCA fails in this setting.
Succinct Inference via Alternating Minimization
It is often the case that the most natural, and computationally tractable, formulation of an inference problem is non-convex, but with the following property: if some subset of the variables are held fixed, the problem is convex in the remaining variables, and vice versa. This naturally suggests alternating minimization as a heuristic; while this is widely employed, our project aims to develop the first theoretical performance guarantees for when such procedures would yield consistent answers.
Our first result, Low-rank Matrix Completion using Alternating Minimization (Symp. on Theory of Computing, 2013) shows that alternating minimization can provably perform matrix completion - under similar settings as when convex optimization works, but with drastically lower space and computation. This saving is important in large-scale settings like collaborative filtering, and naturally allows for distributed implementation.
In subsequent work, Phase Retrieval using Alternating Minimization (submitted) we provide a new algorithm for the classical problem of phase recovery: i.e. solving complex linear equations of the form y = Ax, but when the phase of y is unknown. Again, we show that our algorithm has statistical performance similar to that of convex optimization, but using much lower computational overheard.
Structural Inference in Networks
Inferring the structure and properties of network graphs is a key first step to using network models. In our work, we have focused on using ideas from a very different field - high-dimensional statistics via convex optimization - to solve non-statistical, often non-probabilistic, graph reasoning problems. On the one hand, this allows us to develop methods with state-of-the-art performance guarantees for the problems at hand. On the other hand, it provides a conduit for leveraging exciting recent developments, in solving large-scale convex optimization problems, to the task of large-scale network inference.
Our first focus in this line of work is in graph clustering: given a graph, partition the nodes so that there are (relatively) dense connections within any partition, and sparse across partitions. In Clustering Partially Observed Graphs via Convex Optimization (ICML 2011) we provide a new method based on sparse and low-rank matrix decomposition. The idea is to represent the given graph as the sum of a low-rank “cluster” matrix and a sparse “disagreement” matrix; however our results are stronger than what can be obtained as corollaries of our sparse+low-rank work.
We prove that it is possible to find a graph clustering from a vanishingly small number of edge observations (i.e. for most node pairs we do not even know if there is an edge or not), and for clusters that are as small as 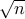 - for the natural and classical “planted partition” or “stochastic block” model of graphs.
- for the natural and classical “planted partition” or “stochastic block” model of graphs.
The above method however is not able to handle sparse graph clustering - finding clusters in graphs where the number of edges is 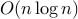 . Sparsity makes the problem noisier and harder. In the paper Clustering sparse graphs (NIPS 2012) we propose a new convex algorithm - based on a subtle re-writing of maximum-likelihood - and prove that it improves on the long line of combinatorial algorithms for sparse graph clustering.
. Sparsity makes the problem noisier and harder. In the paper Clustering sparse graphs (NIPS 2012) we propose a new convex algorithm - based on a subtle re-writing of maximum-likelihood - and prove that it improves on the long line of combinatorial algorithms for sparse graph clustering.
A project along different lines, but hewing to the philosophy of large-scale network inference via convex optimization, concerns the setting of cascades in networks. Cascades, also referred to as epidemic processes, are those where a “contagion” spreads through a network graph; they have been popular models for opinions/content consumption in social networks, viruses in human and computer networks, etc. There has been significant work on understanding how cascades spread on graphs.
We consider the natural, but hitherto un-explored, inverse problem - can we infer the graph, by seeing only the spread of cascades on it ? In the paper Learning the Graph of Epidemic Cascades (SIGMETRICS 2012) we show that it is indeed possible to do so, from a number of observations that scales as 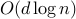 for a network of size
for a network of size 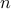 with nodes of degree at most
with nodes of degree at most 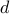 - a high-dimensional scaling. Our method is based on showing that a simple re-parameterization makes Maximum Likelihood a convex program, and further one that is decoupled so that one can fined each node's neighborhood in parallel.
- a high-dimensional scaling. Our method is based on showing that a simple re-parameterization makes Maximum Likelihood a convex program, and further one that is decoupled so that one can fined each node's neighborhood in parallel.
Scheduling Algorithms
The efficient sharing of resources is a key component of communication systems, both wired and wireless. The challenge is to determine which user can access a particular resource at a particular time; algorithms are judged by the computational and coordination overhead they require, and the throughput and delay they can guarantee. This is a classical and widely-studied problem, with several facets. We investigate scheduling in two contexts: wireless networks, and input-queued switches.
In wireless networks, schedules need to be determined in a local fashion. One of the most popular ideas is that of greedy scheduling: a link is turned ON if and only if there is no interfering link with a larger queue that can be ON. Our paper On the Effect of Channel Fading on Greedy Scheduling (INFOCOM, 2012) is the first to characterize the throughput of greedy scheduling in the presence of wireless channel fading. In addition, the paper shows that fading has a very subtle effect on greedy scheduling – it can both help and hurt its performance, as compared to that of an optimal scheduler.
Another popular approach to low-complexity scheduling is via randomized “pick and compare” algorithms: the idea is to iteratively update the schedule by first developing a (random) candidate alternative, and then switching to the alternative if it schedules a set of queues with more aggregate packets. However, this compare step is potentially global in nature. In our paper Distributed Link Scheduling with Constant Overhead (SIGMETRICS, 2007) we develop a local method to compare. This yields the first algorithms which allow for a fixed, pre-specified complexity that can achieve any intended fraction of the throughput; the complexity scales as the inverse of the gap between the intended throughput and the fundamental limits imposed by the system.
In input-queued switches, scheduling can be centralized, but needs to be very fast as the switches are very high throughput. Popular approaches have focused on scheduling “heavy” links – those with large backlog – which translates into finding maximum weight matchings (MWMs). Our paper Node Weighted Scheduling (SIGMETRICS, 2009) develops an alternative approach, focusing on scheduling the heaviest nodes – i.e. input and output ports, weighted by their aggregate queues. This requires solving a node-weighted matching problem, which has order-wise lower complexity, and empirically has lower queues than several previous MWM algorithms.
Graphical models / Markov Random Fields
The classical Markov Random Field (aka Graphical Model) formalism is built on graphical representations of probability distributions; in the Markov graph of a distribution, each node is a variable, and edges represent conditional dependencies. Computationally, MRFs allow for the use of graph algorithms for statistical tasks – see BP project below for our work on this aspect. Statistically, MRFs allow for the more efficient modeling and interpretation of a distribution from samples.
A core problem in MRFs is to learn the Markov graph of a distribution from samples. Any method to do so is judged on two axes: its computational and statistical complexities (i.e. number of operations and samples required, respectively).
A fundamental property of the Markov neighborhood of a node is that it is also its best predictor; for example the neighborhood of a node 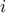 is the set
is the set 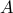 that minimizes the conditional entropy:
that minimizes the conditional entropy: 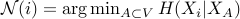 . Exact minimization is intractable; in our first work, we consider a natural greedy algorithm – add nodes one at a time, with each iteration picking the node that provides the biggest marginal reduction in conditional entropy. Statistical performance of this is in our paper Greedy learning of Markov network structure (Allerton, 2010).
. Exact minimization is intractable; in our first work, we consider a natural greedy algorithm – add nodes one at a time, with each iteration picking the node that provides the biggest marginal reduction in conditional entropy. Statistical performance of this is in our paper Greedy learning of Markov network structure (Allerton, 2010).
The above paper and algorithm is for general discrete graphical models. Another approach to learning such models comes via parameterization as exponential families. This allows for the use of convex optimization for learning; specifically, minimizing a loss function and a penalty. The fact that we consider general discrete models means the form of the penalty is group-sparse. On Learning Discrete Graphical Models using Group-Sparse Regularization (AISTATs 2011).
Finally, in Learning Markov Graphs Up To Edit Distance (ISIT 2012) we consider the fundamental limits of learnability, via any algorithm. In particular, we provide lower bounds on the number of samples needed to learn Markov graphs unto edit distance.
Understanding Belief propagation
Belief propagation (BP) is a widely-used method, with several independent origins in statistical physics, error control coding, machine learning etc. It is a distributed parallel mechanism for large-scale computation, one that is exact when the dependencies or constraints between variables can be represented by a tree graph. However, it has been widely used, often with great empirical success, for problems where the graph is not a tree, and can even have several very short cycles. Our motivation was to understand this dichotomy.
In two papers, we show that for certain combinatorial optimization problems, the performance of (the “max product” form of) BP is exactly predicted by the performance of the Linear Programming relaxation of the combinatorial problem. The connection is tightest for the classical weighted matching problem on general graphs, as shown in our paper Belief Propagation and LP Relxation for Weighted Matching in General Graphs (NIPS 2007, Trans. IT). In particular, for weighted matching, BP works if and only if the LP relaxation is tight – we show both the forward and converse parts.
For the classical weighted independent set problem, only the converse holds; BP cannot succeed if LP relaxation fails, as shown in Message Passing for Max-weight Independent Set (NIPS 2007, Trans. IT). We build on the above results to actually use BP as a pure proof technique, to establish the tightness of LP relaxation for a class of random weighted graphs in Independent sets, Tightnessof LP and Max-product.
Finally, on the empirical side, we show that BP presents a natural and appealing distributed procedure for network coordination tasks (facility location, scheduling, routing etc.) in sensor networks; this is as opposed to the more classical use of BP as an inference engine. Results appear in Networking Sensors via Belief Propagation (Allerton, 2008).
Peer-to-peer systems
In the peer-to-peer (p2p) paradigm, nodes act as both consumers and servers of data. In particular, data downloaded by a particular node is subsequently stored and uploaded to other users also looking for the same; this allows service capacity to scale with demand. There are several inter-related issues (lookup, routing, caching, incentives etc.) that arise in the design of a p2p system.
To handle large files, one of the big innovations of second generation p2p systems – like BitTorrent, eDonkey etc. – was to split a large file into pieces, allowing users to start uploading individual pieces without waiting for the complete file. In our work, we look at the issue of piece selection – how do two users determine, locally, which piece should be transferred from one to the other ? Since bandwidth is limited, how this local decision is made has significant effects on the global performance.
In our paper Gossiping with Multiple Messages (Trans. IT) we provide new piece selection algorithms for for p2p systems where data delivery has a real-time constraint, and each node only has partial/no state information about other nodes. We investigate performance in the joint asymptote of large files and large networks, showing that our algorithms achieve within a small constant factor of optimal (centralized) performance.