Chapter 7: Design and Development
Jonathan Valvano and Ramesh Yerraballi
In this chapter, we will begin by presenting a general approach to modular design. In specific, we will discuss how to organize software blocks in an effective manner. The ultimate success of an embedded system project depends both on its software and hardware. Computer scientists pride themselves in their ability to develop quality software. Similarly electrical engineers are well-trained in the processes to design both digital and analog electronics. Manufacturers, in an attempt to get designers to use their products, provide application notes for their hardware devices. The main objective of this class is to combine effective design processes together with practical software techniques in order to develop quality embedded systems. As the size and especially the complexity of the software increase, the software development changes from simple "coding" to "software engineering", and the required skills also vary along this spectrum. These software skills include modular design, layered architecture, abstraction, and verification. Real-time embedded systems are usually on the small end of the size scale, but never the less these systems can be quite complex. Therefore, both hardware and software skills are essential for developing embedded systems. Writing good software is an art that must be developed, and cannot be added on at the end of a project. Just like any other discipline (e.g., music, art, science, religion), expertise comes from a combination of study and practice. The watchful eye of a good mentor can be invaluable, so take the risk and show your software to others inviting praise and criticism. Good software combined with average hardware will always outperform average software on good hardware. In this chapter we will introduce some techniques for developing quality software.
|
Learning Objectives:
|
Video 7.0. Introduction to Embedded System Design |
In this section, we will introduce the product development process in general. The basic approach is introduced here, and the details of these concepts will be presented throughout the remaining chapters of the book. As we learn software/hardware development tools and techniques, we can place them into the framework presented in this section. As illustrated in Figure 7.1, the development of a product follows an analysis-design-implementation-testing-deployment cycle. For complex systems with long life-spans, we transverse multiple times around the life cycle. For simple systems, a one-time pass may suffice.
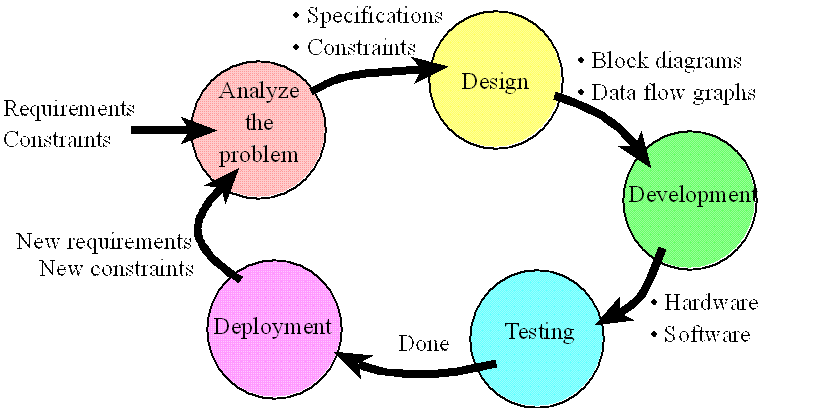
Figure 2.3. Product life cycle.
Video 7.1. Product Life Cycle and Requirements
During the analysis phase, we discover the requirements and constraints for our proposed system. We can hire consultants and interview potential customers in order to gather this critical information. A requirement is a specific parameter that the system must satisfy. We begin by rewriting the system requirements, which are usually written in general form, into a list of detailed specifications. In general, specifications are detailed parameters describing how the system should work. For example, a requirement may state that the system should fit into a pocket, whereas a specification would give the exact size and weight of the device. For example, suppose we wish to build a motor controller. During the analysis phase, we would determine obvious specifications such as range, stability, accuracy, and response time. There may be less obvious requirements to satisfy, such as weight, size, battery life, product life, ease of operation, display readability, and reliability. Often, improving the performance on one parameter can be achieved only by decreasing the performance of another. This art of compromise defines the tradeoffs an engineer must make when designing a product. A constraint is a limitation, within which the system must operate. The system may be constrained to such factors as cost, safety, compatibility with other products, use of specific electronic and mechanical parts as other devices, interfaces with other instruments and test equipment, and development schedule. The following measures are often considered during the analysis phase of a project:
Safety: The risk to humans or the environment
Accuracy: The difference between the expected truth and the actual parameter
Precision: The number of distinguishable measurements
Resolution: The smallest change that can be reliably detected
Response time: The time between a triggering event and the resulting action
Bandwidth: The amount of information processed per time
Maintainability: The flexibility with which the device can be modified
Testability: The ease with which proper operation of the device can be verified
Compatibility: The conformance of the device to existing standards
Mean time between failure: The reliability of the device, the life of a product
Size and weight: The physical space required by the system
Power: The amount of energy it takes to operate the system
Nonrecurring engineering cost (NRE cost): The one-time cost to design and test
Unit cost: The cost required to manufacture one additional product
Time-to-prototype: The time required to design, build, and test an example system
Time-to-market: The time required to deliver the product to the customer
Human factors: The degree to which our customers like/appreciate the product
: What’s the difference between a requirement and a specification?
The following is one possible outline of a Requirements Document. IEEE publishes a number of templates that can be used to define a project (IEEE STD 830-1998). A requirements document states what the system will do. It does not state how the system will do it. The main purpose of a requirements document is to serve as an agreement between you and your clients describing what the system will do. This agreement can become a legally binding contract. Write the document so that it is easy to read and understand by others. It should be unambiguous, complete, verifiable, and modifiable.
1. Overview
1.1. Objectives: Why are we doing this project? What is the purpose?
1.2. Process: How will the project be developed?
1.3. Roles and Responsibilities: Who will do what? Who are the clients?
1.4. Interactions with Existing Systems: How will it fit in?
1.5. Terminology: Define terms used in the document.
1.6. Security: How will intellectual property be managed?
2. Function Description
2.1. Functionality: What will the system do precisely?
2.2. Scope: List the phases and what will be delivered in each phase.
2.3. Prototypes: How will intermediate progress be demonstrated?
2.4. Performance: Define the measures and describe how they will be determined.
2.5. Usability: Describe the interfaces. Be quantitative if possible.
2.6. Safety: Explain any safety requirements and how they will be measured.
3. Deliverables
3.1. Reports: How will the system be described?
3.2. Audits: How will the clients evaluate progress?
3.3. Outcomes: What are the deliverables? How do we know when it is done?
Observation: To build a system without a requirements document means you are never wrong, but never done.
When we begin the design phase, we build a conceptual model of the hardware/software system. It is in this model that we exploit as much abstraction as appropriate. The project is broken into modules or subcomponents. During this phase, we estimate the cost, schedule, and expected performance of the system. At this point we can decide if the project has a high enough potential for profit. A data flow graph is a block diagram of the system, showing the flow of information. Arrows point from source to destination. The rectangles represent hardware components, and the ovals are software modules. We use data flow graphs in the high-level design, because they describe the overall operation of the system while hiding the details of how it works. Issues such as safety (e.g., Isaac Asimov’s first Law of Robotics “A robot may not harm a human being, or, through inaction, allow a human being to come to harm”) and testing (e.g., we need to verify our system is operational) should be addressed during the high-level design. A data flow graph for a simple position measurement system is shown in Figure 7.2. The sensor converts position in an electrical resistance. The analog circuit converts resistance into the 0 to +3V voltage range required by the ADC. The ADC converts analog voltage into a digital sample. The ADC driver, using the ADC and timer hardware, collects samples and calculates voltages. The software converts voltage to position. Voltage and position data are represented as fixed-point numbers within the computer. The position data is passed to the OLED driver creating ASCII strings, which will be sent to the organic light emitting diode (OLED) module.
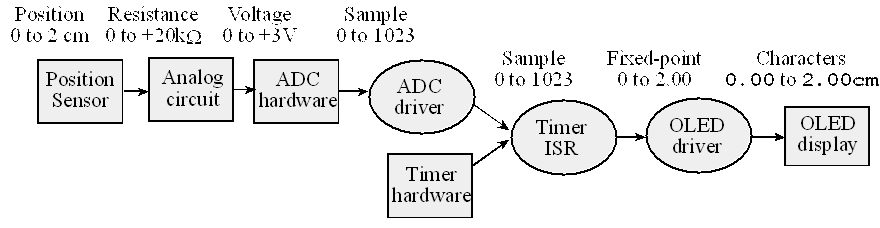
Figure 7.2. A data flow graph showing how the position signal passes through the system.
A preliminary design includes the overall top-down hierarchical structure, the basic I/O signals, shared data structures, and overall software scheme. At this stage there should be a simple and direct correlation between the hardware/software systems and the conceptual model developed in the high-level design. Next, we finish the top-down hierarchical structure and build mock-ups of the mechanical parts (connectors, chassis, cables etc.) and user software interface. Sophisticated 3-D CAD systems can create realistic images of our system. Detailed hardware designs must include mechanical drawings. It is a good idea to have a second source, which is an alternative supplier that can sell our parts if the first source can’t deliver on time. Call graphs are a graphical way to define how the software/hardware modules interconnect. Data structures, which will be presented throughout the class, include both the organization of information and mechanisms to access the data. Again safety and testing should be addressed during this low-level design.
A call graph for a simple position measurement system is shown in Figure 7.3. Again, rectangles represent hardware components, and ovals show software modules. An arrow points from the calling routine to the module it calls. The I/O ports are organized into groups and placed at the bottom of the graph. A high-level call graph, like the one shown in Figure 7.3, shows only the high-level hardware/software modules. A detailed call graph would include each software function and I/O port. Normally, hardware is passive and the software initiates hardware/software communication, but as we will learn in this book, it is possible for the hardware to interrupt the software and cause certain software modules to be run. In this system, the timer hardware will cause the ADC software to collect a sample. The timer interrupt service routine (ISR) gets the next sample from the ADC software, converts it to position, and displays the result by calling the OLED interface software. The double-headed arrow between the ISR and the hardware means the hardware triggers the interrupt and the software accesses the hardware.
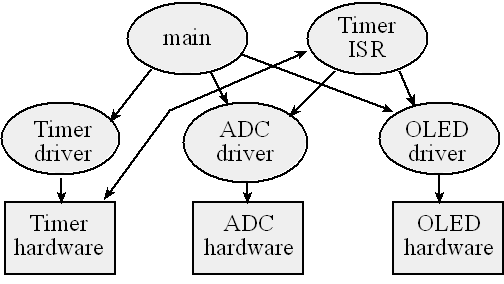
Figure 7.3. A call graph for a simple position measurement system.
Observation: If module A calls module B, and B returns data, then a data flow graph will show an arrow from B to A, but a call graph will show an arrow from A to B.
The next phase involves developing an implementation. An advantage of a top-down design is that implementation of subcomponents can occur simultaneously. During the initial iterations of the life cycle, it is quite efficient to implement the hardware/software using simulation. One major advantage of simulation is that it is usually quicker to implement an initial product on a simulator versus constructing a physical device out of actual components. Rapid prototyping is important in the early stages of product development. This allows for more loops around the analysis-design-implementation-testing-deployment cycle, which in turn leads to a more sophisticated product.
Recent software and hardware technological developments have made significant impacts on the software development for embedded microcomputers. The simplest approach is to use a cross-assembler or cross-compiler to convert source code into the machine code for the target system. The machine code can then be loaded into the target machine. Debugging embedded systems with this simple approach is very difficult for two reasons. First, the embedded system lacks the usual keyboard and display that assist us when we debug regular software. Second, the nature of embedded systems involves the complex and real-time interaction between the hardware and software. These real-time interactions make it impossible to test software with the usual single-stepping and print statements.
The next technological advancement that has greatly affected the manner in which embedded systems are developed is simulation. Because of the high cost and long times required to create hardware prototypes, many preliminary feasibility designs are now performed using hardware/software simulations. A simulator is a software application that models the behavior of the hardware/software system. If both the external hardware and software program are simulated together, even though the simulated time is slower than the clock on the wall, the real-time hardware/software interactions can be studied.
During the testing phase, we evaluate the performance of our system. First, we debug the system and validate basic functions. Next, we use careful measurements to optimize performance such as static efficiency (memory requirements), dynamic efficiency (execution speed), accuracy (difference between expected truth and measured), and stability (consistent operation.) Debugging techniques will be presented at the end of most chapters.
Maintenance is the process of correcting mistakes, adding new features, optimizing for execution speed or program size, porting to new computers or operating systems, and reconfiguring the system to solve a similar problem. No system is static. Customers may change or add requirements or constraints. To be profitable, we probably will wish to tailor each system to the individual needs of each customer. Maintenance is not really a separate phase, but rather involves additional loops around the life cycle.
Figure 7.1 describes top-down design as a cyclic process, beginning with a problem statement and ending up with a solution. With a bottom-up design we begin with solutions and build up to a problem statement. Many innovations begin with an idea, “what if…?” In a bottom-up design, one begins with designing, building, and testing low-level components. The low-level designs can be developed in parallel. Bottom-up design may be inefficient because some subsystems may be designed, built, and tested, but never used. As the design progresses the components are fit together to make the system more and more complex. Only after the system is completely built and tested does one define the overall system specifications. The bottom-up design process allows creative ideas to drive the products a company develops. It also allows one to quickly test the feasibility of an idea. If one fully understands a problem area and the scope of potential solutions, then a top-down design will arrive at an effective solution most quickly. On the other hand, if one doesn’t really understand the problem or the scope of its solutions, a bottom-up approach allows one to start off by learning about the problem.
Throughout the book in general, we discuss how to solve problems on the computer. In this section, we discuss the process of converting a problem statement into an algorithm. Later in the book, we will show how to map algorithms into assembly language. We begin with a set of general specifications, and then create a list of requirements and constraints. The general specifications describe the problem statement in an overview fashion, requirements define the specific things the system must do, and constraints are the specific things the system must not do. These requirements and constraints will guide us as we develop and test our system.
Observation: Sometimes the specifications are ambiguous, conflicting, or incomplete.
There are two approaches to the situation of ambiguous, conflicting, or incomplete specifications. The best approach is to resolve the issue with your supervisor or customer. The second approach is to make a decision and document the decision.
Performance Tip: If you feel a system specification is wrong, discuss it with your supervisor. We can save a lot of time and money by solving the correct problem in the first place.
Successive refinement, stepwise refinement, and systematic decomposition are three equivalent terms for a technique to convert a problem statement into a software algorithm. We start with a task and decompose the task into a set of simpler subtasks. Then, the subtasks are decomposed into even simpler sub-subtasks. We make progress as long as each subtask is simpler than the task itself. During the task decomposition we must make design decisions as the details of exactly how the task will be performed are put into place. Eventually, a subtask is so simple that it can be converted to software code. We can decompose a task in four ways, as shown in Figure 2.6. The sequence, conditional, and iteration are the three building blocks of structured programming. Because embedded systems often have real-time requirements, they employ a fourth building block called interrupts. We will implement time-critical tasks using interrupts, which are hardware-triggered software functions. Interrupts will be discussed in more detail in Chapters 9, 10, and 11. When we solve problems on the computer, we need to answer these questions:
· What does being in a state mean? List the parameters of the state
· What is the starting state of the system? Define the initial state
· What information do we need to collect? List the input data
· What information do we need to generate? List the output data
· How do we move from one state to another? Specify actions we could perform
· What is the desired ending state? Define the ultimate goal
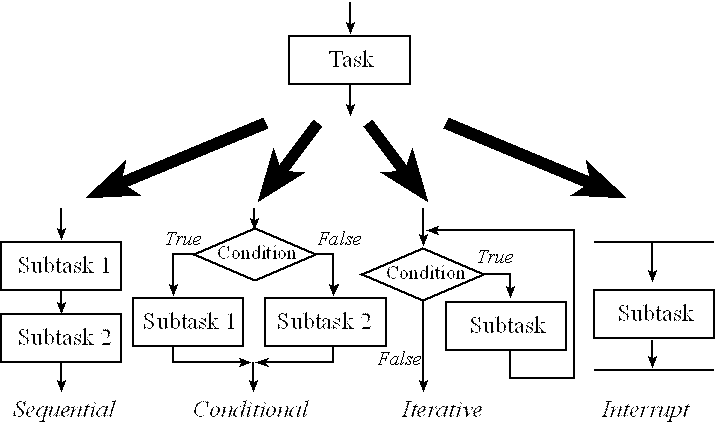
Figure 7.4. We can decompose a task using the building blocks of structured programming.
We need to recognize these phrases that translate to four basic building blocks:
· “do A then do B” → sequential
· “do A and B in either order” → sequential
· “if A, then do B” → conditional
· “for each A, do B” → iterative
· “do A until B” → iterative
· “repeat A over and over forever” → iterative (condition always true)
· “on external event do B” → interrupt
· “every t msec do B” → interrupt
Example 7.0. Build a digital door lock using seven switches.
The
animation below
shows how successive refinement is done in designing a solution to this
problem. Click on the expand button to generate new flowcharts.
Embedded system development is similar to other engineering tasks. We can choose to follow well-defined procedures during the development and evaluation phases, or we can meander in a haphazard way and produce code that is hard to test and harder to change. The ultimate goal of the system is to satisfy the stated objectives such as accuracy, stability, and input/output relationships. Nevertheless it is appropriate to separately evaluate the individual components of the system. Therefore in this section, we will evaluate the quality of our software. There are two categories of performance criteria with which we evaluate the “goodness” of our software. Quantitative criteria include dynamic efficiency (speed of execution), static efficiency (memory requirements), and accuracy of the results. Qualitative criteria center on ease of software maintenance. Another qualitative way to evaluate software is ease of understanding. If your software is easy to understand then it will be:
Easy to debug (fix mistakes)
Easy to verify (prove correctness)
Easy to maintain (add features)
Common Error: Programmers who sacrifice clarity in favor of execution speed often develop software that runs fast, but is error-prone and difficult to change.
Golden Rule of Software Development
Write software for others as you wish they would write for you.
In order to evaluate our software quality, we need performance measures. The simplest approaches to this issue are quantitative measurements. Dynamic efficiency is a measure of how fast the program executes. It is measured in seconds or processor bus cycles. Static efficiency is the number of memory bytes required. Since most embedded computer systems have both RAM and ROM, we specify memory requirement in global variables, stack space, fixed constants and program. The global variables plus the stack must fit into the available RAM. Similarly, the fixed constants plus the program must fit into the available ROM. We can also judge our embedded system according to whether or not it satisfies given requirements and constraints, like accuracy, cost, power, size, reliability, and time-table.
Qualitative performance measurements include those parameters to which we cannot assign a direct numerical value. Often in life the most important questions are the easiest to ask, but the hardest to answer. Such is the case with software quality. So therefore we ask the following qualitative questions. Can we prove our software works? Is our software easy to understand? Is our software easy to change? Since there is no single approach to writing the best software, we can only hope to present some techniques that you may wish to integrate into your own software style. In fact, this book devotes considerable effort to the important issue of developing quality software. In particular, we will study self-documented code, abstraction, modularity, and layered software. These issues indeed play a profound effect on the bottom-line financial success of our projects. Although quite real, because there is often not an immediate and direct relationship between a software’s quality and profit, we may be mistakenly tempted to dismiss the importance of quality.
To get a benchmark on how good a programmer you are, take the following two challenges. In the first challenge, find a major piece of software that you have written over 12 months ago, and then see if you can still understand it enough to make minor changes in its behavior. The second challenge is to exchange with a peer a major piece of software that you have both recently written (but not written together), then in the same manner, see if you can make minor changes to each other's software.
Observation: You can tell if you are a good programmer if 1) you can understand your own code 12 months later, and 2) others can make changes to your code.
Good engineers employ well-defined design processes when developing complex systems. When we work within a structured framework, it is easier to prove our system works (verification) and to modify our system in the future (maintenance.) As our software systems become more complex, it becomes increasingly important to employ well-defined software design processes. Throughout this book, a very detailed set of software development rules will be presented. This class focuses on real-time embedded systems written in C, but most of the design processes should apply to other languages as well. At first, it may seem radical to force such a rigid structure to software. We might wonder if creativity will be sacrificed in the process. True creativity is more about good solutions to important problems and not about being sloppy and inconsistent. Because software maintenance is a critical task, the time spent organizing, documenting, and testing during the initial development stages will reap huge dividends throughout the life of the software project.
Observation: The easiest way to debug is to write software without any bugs.
We define clients as programmers who will use our software. A client develops software that will call our functions. We define coworkers as programmers who will debug and upgrade our software. A coworker, possibly ourselves, develops, tests, and modifies our software.
Writing quality software has a lot to do with attitude. We should be embarrassed to ask our coworkers to make changes to our poorly written software. Since so much software development effort involves maintenance, we should create software modules that are easy to change. In other words, we should expect each piece of our code will be read by another engineer in the future, whose job it will be to make changes to our code. We might be tempted to quit a software project once the system is running, but this short time we might save by not organizing, documenting, and testing will be lost many times over in the future when it is time to update the code.
As project managers, we must reward good behavior and punish bad behavior. A company, in an effort to improve the quality of their software products, implemented the following policies.
The employees in the customer relations department receive a bonus for every software bug that they can identify. These bugs are reported to the software developers, who in turn receive a bonus for every bug they fix.
: Why did the above policy fail horribly?
We should demand of ourselves that we deliver bug-free software to our clients. Again, we should be embarrassed when our clients report bugs in our code. We should be mortified when other programmers find bugs in our code. There are a few steps we can take to facilitate this important aspect of software design.
Test it now. When we find a bug, fix it immediately. The longer we put off fixing a mistake the more complicated the system becomes, making it harder to find. Remember that bugs do not go away on their own, but we can make the system so complex that the bugs will manifest themselves in mysterious and obscure ways. For the same reason, we should completely test each module individually, before combining them into a larger system. We should not add new features before we are convinced the existing system is bug-free. In this way, we start with a working system, add features, and then debug this system until it is working again. This incremental approach makes it easier to track progress. It allows us to undo bad decisions, because we can always revert back to a previously working system. Adding new features before the old ones are debugged is very risky. With this sloppy approach, we could easily reach the project deadline with 100% of the features implemented, but have a system that doesn’t run. In addition, once a bug is introduced, the longer we wait to remove it, the harder it will be to correct. This is particularly true when the bugs interact with each other. Conversely, with the incremental approach, when the project schedule slips, we can deliver a working system at the deadline that supports some of the features.
Maintenance Tip: Go from working system to working system.
Plan for testing. How to test each module should be considered at the start of a project. In particular, testing should be included as part of the design of both hardware and software components. Our testing and the client's usage go hand in hand. In particular, how we test the module will help the client understand the context and limitations of how our component is to be used. On the other hand, a clear understanding of how the client wishes to use our hardware/software component is critical for both its design and its testing.
Maintenance Tip: It is better to have some parts of the system that run with 100% reliability than to have the entire system with bugs.
Get help. Use whatever features are available for organization and debugging. Pay attention to warnings, because they often point to misunderstandings about data or functions. Misunderstanding of assumptions that can cause bugs when the software is upgraded, or reused in a different context than originally conceived. Remember that computer time is a lot cheaper than programmer time.
Maintenance Tip: It is better to have a system that runs slowly than to have one that doesn’t run at all.
Deal with the complexity. In the early days of microcomputer systems, software size could be measured in 100’s of lines of source code using 1000’s of bytes of memory. These early systems, due to their small size, were inherently simple. The explosion of hardware technology (both in speed and size) has led to a similar increase in the size of software systems. Some people forecast that by the next decade, automobiles will have 10 million lines of code in their embedded systems. The only hope for success in a large software system will be to break it into simple modules. In most cases, the complexity of the problem itself cannot be avoided. E.g., there is just no simple way to get to the moon. Nevertheless, a complex system can be created out of simple components. A real creative effort is required to orchestrate simple building blocks into larger modules, which themselves are grouped to create even larger systems. Use your creativity to break a complex problem into simple components, rather than developing complex solutions to simple problems.
Observation: There are two ways of constructing a software design: one way is to make it so simple that there are obviously no deficiencies and the other way is make it so complicated that there are no obvious deficiencies. C.A.R. Hoare, "The Emperor's Old Clothes," CACM Feb. 1981.
A program module that performs a well-defined task can be packaged up and defined as a single entity. Functions in that module can be invoked whenever a task needs to be performed. Object-oriented high-level languages like C++ and Java define program modules as methods. Functions and procedures are defined in some high-level languages like Pascal, FORTRAN, and Ada. In these languages, functions return a parameter and procedures do not. Most high-level languages however define program modules as functions, whether they return a parameter or not. A subroutine is the assembly language version of a function. Consequently, subroutines may or may not have input or output parameters. Formally, there are two components to a subroutine: definition and invocation. The subroutine definition specifies the task to be performed. In other words, it defines what will happen when executed. The syntax for an assembly subroutine begins with a label, which will be the name of the subroutine and ends with a return instruction. The definition of a subroutine includes a formal specification its input parameters and output parameters. In well-written software, the task performed by a subroutine will be well-defined and logically complete. The subroutine invocation is inserted to the software system at places when and where the task should be performed. We define software that invokes the subroutine as “the calling program” because it calls the subroutine. There are three parts to a subroutine invocation: pass input parameters, subroutine call, and accept output parameters. If there are input parameters, the calling program must establish the values for input parameters before it calls the subroutine. A BL instruction is used to call the subroutine. After the subroutine finishes, and if there are output parameters, the calling program accepts the return value(s). In this chapter, we will pass parameters using the registers. If the register contains a value, the parameter is classified as call by value. If the register contains an address, which points to the value, then the parameter is classified as call by reference.
: What is the difference between call by value and call by reference?
For example, consider a subroutine that samples the 12-bit ADC, as drawn in Figure 7.1. An analog input signal is connected to ADC0. The details of how the ADC works will be presented later in the class, but for now we focus on the defining and invoking subroutines. The execution sequence begins with the calling program setting up the input parameters. In this case, the calling program sets Register R0 equal to the channel number, MOV R0,#0. The instruction BL ADC_In will save the return address in the LR register and jump to the ADC_In subroutine. The subroutine performs a well-defined task. In this case, it takes the channel number in Register R0 and performs an analog to digital conversion, placing the digital representation of the analog input into Register R0. The BX LR instruction will move the return address into the PC, returning the execution thread to the instruction after the BL in the calling program. In this case, the output parameter in Register R0 contains the result of the ADC conversion. It is the responsibility of the calling program to accept the return parameter. In this case, it simply stores the result into variable n. In this example, both the input and output parameters are call by value.
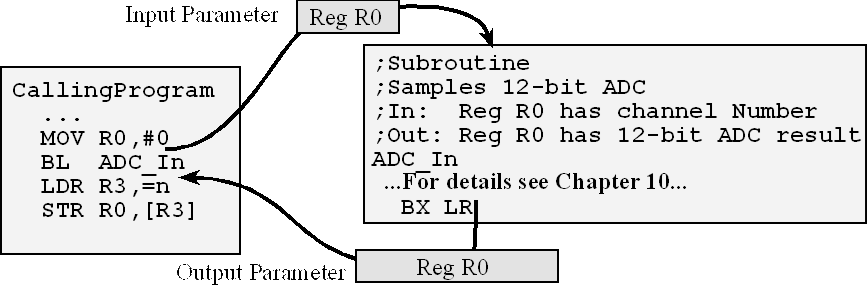
Figure 7.1. The calling program invokes the ADC_In subroutine passing parameters in registers.
The overall goal of modular programming is to enhance clarity. The smaller the task, the easier it will be to understand. Coupling is defined as the influence one module’s behavior has on another module. In order to make modules more independent we strive to minimize coupling. Obvious and appropriate examples of coupling are the input/output parameters explicitly passed from one module to another. A quantitative measure of coupling is the number of bytes per second (bandwidth) that are transferred from one module to another. On the other hand, information stored in public global variables can be quite difficult to track. In a similar way, shared accesses to I/O ports can also introduce unnecessary complexity. Public global variables cause coupling between modules that complicate the debugging process because now the modules may not be able to be separately tested. On the other hand, we must use global variables to pass information into and out of an interrupt service routine and from one call to an interrupt service routine to the next call. When passing data into or out of an interrupt service routine, we group the functions that access the global into the same module, thereby making the global variable private. Another problem specific to embedded systems is the need for fast execution, coupled with the limited support for local variables. On many microcontrollers it is inefficient to implement local variables on the stack. Consequently, many programmers opt for the less elegant yet faster approach of global variables. Again, if we restrict access to these globals to function in the same module, the global becomes private. It is poor design to pass data between modules through public global variables; it is better to use a well-defined abstract technique like a FIFO queue.
We should assign a logically complete task to each module. The module is logically complete when it can be separated from the rest of the system and placed into another application. The interface design is extremely important. The interface to a module is the set of public functions that can be called and the formats for the input/output parameters of these functions. The interfaces determine the policies of our modules: “What does the module do?” In other words, the interfaces define the set of actions that can be initiated. The interfaces also define the coupling between modules. In general we wish to minimize the bandwidth of data passing between the modules yet maximize the number of modules. Of the following three objectives when dividing a software project into subtasks, it is really only the first one that matters
• Make the software project easier to understand
• Increase the number of modules
• Decrease the interdependency (minimize bandwidth between modules).
: List some examples of coupling.
We will illustrate the process of dividing a software task into modules with an abstract but realistic example. The overall goal of the example shown in Figure 7.2 is to sample data using an ADC, perform calculations on the data, and output results. The organic light emitting diode (OLED) could be used to display data to the external world. Notice the typical format of an embedded system in that it has some tasks performed once at the beginning, and it has a long sequence of tasks performed over and over. The structure of this example applies to many embedded systems such as a diagnostic medical instrument, an intruder alarm system, a heating/AC controller, a voice recognition module, automotive emissions controller, or military surveillance system. The left side of Figure 7.2 shows the complex software system defined as a linear sequence of ten steps, where each step represents many lines of assembly code. The linear approach to this program follows closely to linear sequence of the processor as it executes instructions. This linear code, however close to the actual processor, is difficult to understand, hard to debug, and impossible to reuse for other projects. Therefore, we will attempt a modular approach considering the issues of functional abstraction, complexity abstraction, and portability in this example. The modular approach to this problem divides the software into three modules containing seven subroutines. In this example, assume the sequence Step4-Step5-Step6 causes data to be sorted. Notice that this sorting task is executed twice.
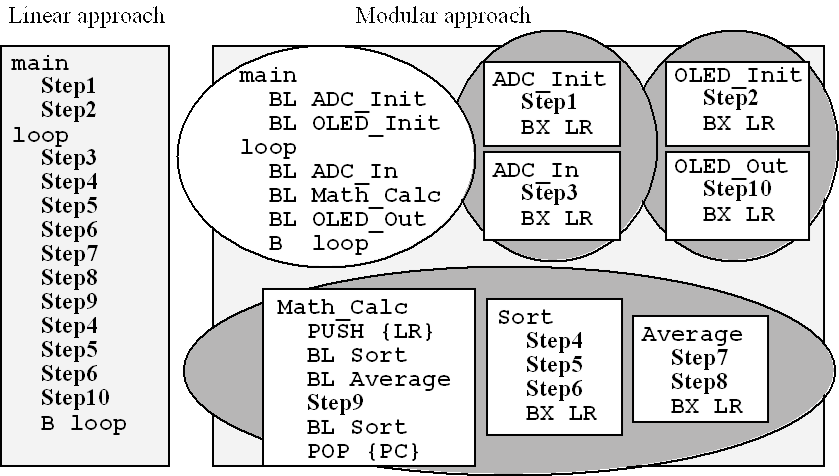
Figure 7.2. A complex software system is broken into three modules containing seven subroutines.
Functional abstraction encourages us to create a Sort subroutine allowing us to write the software once, but execute it from different locations. Complexity abstraction encourages us to organize the ten-step software into a main program with multiple modules, where each module has multiple subroutines. For example, assume the assembly instructions in Step1 cause the ADC to be initialized. Even though this code is executed only once, complexity abstraction encourages us to create an ADC_Init subroutine so the system is easier to understand and easier to debug. In a similar way assume Step2 initializes the OLED port, Step3 samples the ADC, the sequence Step7-Step8 performs an average, and Step10 outputs to the OLED. Therefore, each well-defined task is defined as a separate subroutine. The subroutines are then grouped into modules. For example, the ADC module is a collection of subroutines that operate the ADC. The complex behavior of the ADC is now abstracted into two easy to understand tasks: turn it on, and use it. In a similar way, the OLED module includes all functions that access the OLED. Again, at the abstract level of the main program, understanding how to use the OLED is a matter knowing we first turn it on then we transmit data. The math module is a collection of subroutines to perform necessary calculations on the data. In this example, we assume sort and average will be private subroutines, meaning they can be called only by software within the math module and not by software outside the module. Making private subroutines is an example of “information hiding”, separating what the module does from how the module works. When we port a system, it means we take a working system and redesign it with some minor but critical change. The OLED device is used in this system to output results. We might be asked to port this system onto a device that uses an LCD in place of the OLED for its output. In this case, all we need to do is design, implement and test an LCD module with two subroutines LCD_Init and LCD_Out that function in a similar manner as the existing OLED routines. The modular approach performs the exact same ten steps in the exact same order. However, the modular approach is easier to debug, because first we debug each subroutine, then we debug each module, and finally we debug the entire system. The modular approach clearly supports code reuse. For example, if another system needs an ADC, we can simply use the ADC module software without having to debug it again.
Observation: When writing modular code, notice its two-dimensional aspect. Down the y-axis still represents time as the program is executed, but along the x-axis we now visualize a functional block diagram of the system showing its data flow: input, calculate, output.
The previous section presented fundamental concepts and general approaches to solving problems on the computer. In the subsequent sections, detailed implementations will be presented.
7.5.1. Conditional if-then Statements
Decision making is an important aspect of software programming. Two values are compared and certain blocks of program are executed or skipped depending on the results of the comparison. In assembly language it is important to know the precision (e.g., 8-bit, 16-bit, 32-bit) and the format of the two values (e.g., unsigned, signed). It takes three steps to perform a comparison. You begin by reading the first value into a register. If the second value is not a constant, it must be read into a register, too. The second step is to compare the first value with the second value. You can use either a subtract instruction with the S (SUBS) or a compare instruction (CMP CMN). The CMP CMN SUBS instructions set the condition code bits. The last step is a conditional branch.
Observation: Think of the three steps 1) bring first value into a register, 2) compare to second value, 3) conditional branch, bxx (where xx is eq ne lo ls hi hs gt ge lt or le). The branch will occur if (first is xx second).
In Programs 71 and 7.2, we assume G is a 32-bit unsigned variable. Program 7.1 contains two separate if-then structures involving testing for equal or not equal. It will call GEqual7 if G equals 7, and GNotEqual7 if G does not equal 7. When testing for equal or not equal it doesn’t matter whether the numbers are signed or unsigned. However, it does matter if they are 8-bit or 16-bit. To convert these examples to 16 bits, use the LDRH R0,[R2] instruction instead of the LDR R0,[R2] instruction. To convert these examples to 8 bits, use the LDRB R0,[R2] instruction instead of the LDR R0,[R2] instruction.
|
Assembly code |
C code |
|
LDR R2, =G ; R2 = &G LDR R0, [R2] ; R0 = G CMP R0, #7 ; is G == 7 ? BNE next1 ; if not, skip BL GEqual7 ; G == 7 next1 |
unsigned long G; if(G == 7){ GEqual7(); } |
|
LDR R2, =G ; R2 = &G LDR R0, [R2] ; R0 = G CMP R0, #7 ; is G != 7 ? BEQ next2 ; if not, skip BL GNotEqual7 ; G != 7 next2 |
if(G != 7){ GNotEqual7(); } |
Program 7.1. Conditional structures that test for equality (this works with signed and unsigned numbers).
When testing for greater than or less than, it does matter whether the numbers are signed or unsigned. Program 7.2 contains four separate unsigned if-then structures. In each case, the first step is to bring the first value in R0; the second step is to compare the first value with a second value; and the third step is to execute an unsigned branch Bxx. The branch will occur if the first unsigned value is xx the second unsigned value.
|
Assembly code |
C code |
|
LDR R2, =G ; R2 = &G LDR R0, [R2] ; R0 = G CMP R0, #7 ; is G > 7? BLS next1 ; if not, skip BL GGreater7 ; G > 7 next1 |
unsigned long G; if(G > 7){ GGreater7(); } |
|
LDR R2, =G ; R2 = &G LDR R0, [R2] ; R0 = G CMP R0, #7 ; is G >= 7? BLO next2 ; if not, skip BL GGreaterEq7 ; G >= 7 next2 |
if(G >= 7){ GGreaterEq7(); } |
|
LDR R2, =G ; R2 = &G LDR R0, [R2] ; R0 = G CMP R0, #7 ; is G < 7? BHS next3 ; if not, skip BL GLess7 ; G < 7 next3 |
if(G < 7){ GLess7(); } |
|
LDR R2, =G ; R2 = &G LDR R0, [R2] ; R0 = G CMP R0, #7 ; is G <= 7? BHI next4 ; if not, skip BL GLessEq7 ; G <= 7 next4 |
if(G <= 7){ GLessEq7(); } |
Program 7.2. Unsigned conditional structures.
It will call GGreater7 if G is greater than 7, GGreaterEq7 if G is greater than or equal to 7, GLess7 if G is less than 7, and GLessEq7 if G is less than or equal to 7. When comparing unsigned values, the instructions BHI BLO BHS and BLS should follow the subtraction or comparison instruction. A conditional if-then is implemented by bringing the first number in a register, subtracting the second number, then using the branch instruction with complementary logic to skip over the body of the if-then. To convert these examples to 16 bits, use the LDRH R0,[R2] instruction instead of the LDR R0,[R2] instruction. To convert these examples to 8 bits, use the LDRB R0,[R2] instruction instead of the LDR R0,[R2] instruction.
If-Then
Statement -
The statements inside an if statement will execute once if the
condition is true. If the condition is false, the program will skip
those instructions. Choose two unsigned integers as variables a and b,
press run and follow the flow of the program and examine the output
screen. You can repeat the process with different variables.
variable a:
variable b:
| C Code | |
|---|---|
|
volatile long a; volatile long b; int main () { printf("Starting the Construct ...\n"); if (a<b){ printf("a is less than b\n"); } printf("Ending the Construct ...\n"); return 0; } |
|
| Output Screen | |
Example 7.1. Assuming G1 is 8-bit unsigned, write software that sets G1=50 if G1 is greater than 50. In other words, we will force G1 into the range 0 to 50
Solution: First, we draw a flowchart describing the desired algorithm, see Figure 7.3. Next, we restate the conditional as “skip over if G1 is less than or equal to 50”. To implement the assembly code we bring G1 into Register R0 using LDRB to load an unsigned byte, subtract 50, then branch to next if G1 is less than or equal to 50, as presented in Program 7.3. We will use an unsigned conditional branch because the data format is unsigned.
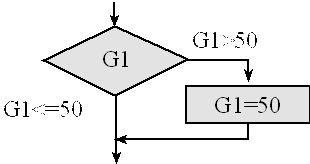
Figure 7.3. Flowchart of an if-then structure.
|
LDR R2, =G1 ; R2 = &G1 LDRB R0, [R2] ; R0 = G1 CMP R0, #50 ; is G1 > 50? BLS next ; if not, skip to end MOV R1, #50 ; R1 = 50 STRB R1, [R2] ; G1 = 50 next |
unsigned char G1; if(G1>50){ G1 = 50; }
|
Program 7.3. An unsigned if-then structure. LDRB used because 8-bit, BLS used because it is unsigned.
: Assume you have an 8-bit unsigned global variable N. Write C code that executes the function isTen, if N is equal to 10.
: Assume H1 and H2 are two 16-bit unsigned variables. Write C code that executes the function isEqual if H1 equals H2.
Program 7.4 contains four separate signed if-then structures, where G is signed 32 bits. In each case, the first step is to bring the first value in R0; the second step is to compare the first value with a second value; and the third step is to execute a signed branch Bxx. The branch will occur if the first signed value is xx the second signed value.
|
Assembly code |
C code |
|
LDR R2, =G ; R2 = &G LDR R0, [R2] ; R0 = G CMP R0, #7 ; is G > 7? BLE next1 ; if not, skip BL GGreater7 ; G > 7 next1 |
long G; if(G > 7){ GGreater7(); } |
|
LDR R2, =G ; R2 = &G LDR R0, [R2] ; R0 = G CMP R0, #7 ; is G >= 7? BLT next2 ; if not, skip BL GGreaterEq7 ; G >= 7 next2 |
if(G >= 7){ GGreaterEq7(); } |
|
LDR R2, =G ; R2 = &G LDR R0, [R2] ; R0 = G CMP R0, #7 ; is G < 7? BGE next3 ; if not, skip BL GLess7 ; G < 7 next3 |
if(G < 7){ GLess7(); } |
|
LDR R2, =G ; R2 = &G LDR R0, [R2] ; R0 = G CMP R0, #7 ; is G <= 7? BGT next4 ; if not, skip BL GLessEq7 ; G <= 7 next4 |
if(G <= 7){ GLessEq7(); } |
Program 7.4. Signed conditional structures.
Similar to Program 7.2, Program 7.4 will call GGreater7 if G is greater than 7, GGreaterEq7 if G is greater than or equal to 7, GLess7 if G is less than 7, and GLessEq7 if G is less than or equal to 7. When comparing signed values, the instructions BGT BLT BGE and BLE should follow the subtraction or comparison instruction. A conditional if-then is implemented by bringing the first number in a register, subtracting the second number, then using the branch instruction with complementary logic to skip over the body of the if-then. To convert these examples to 16 bits, use the LDRSH R0,[R2] instruction instead of the LDR R0,[R2] instruction. To convert these examples to 8 bits, use the LDRSB R0,[R2] instruction instead of the LDR R0,[R2] instruction.
: Assume you have a 32-bit signed global variable N. Write C code that executes the function isNeg, if N is negative.
Common error: It is an error to use an unsigned conditional branch when comparing two signed values. Similarly, it is a mistake to use a signed conditional branch when comparing two unsigned values.
Observation: One cannot directly compare a signed number to an unsigned number. The proper method is to first convert both numbers to signed numbers of a higher precision and then compare.
Example 7.2. Redesign the Example 7.1 code assuming G1 is 8-bit signed. In particular we restrict the range to -128 to +50.
Solution: We can use the same flowchart shown previously in Figure 7.3. The way to compare two values is to subtract them from each other and check if that subtraction resulted in a positive number, zero, or negative number. If the subtraction yields a zero, then the numbers are obviously equal and the Z bit will be set. If it is positive, that means the first value is bigger than the second value and the N bit will be 0. If it is negative, then the first value is smaller than the second one and the N bit will be 1. In this case we bring G1 into Register R0 this time using LDRSB to load a signed byte (first value), and subtract 50 (second value). The CMP instruction subtracts 50 from R0 but doesn't save the result, it just sets the condition codes. The BLE uses the condition codes to branch to next if G1 is less than or equal to 50, as presented in Program 7.5. However, we will use a signed conditional branch (BLE) because the data format is signed..
|
LDR R2, =G1 ; R2 = &G1 LDRSB R0, [R2] ; R0 = G1 (signed) CMP R0, #50 ; is G1 > 50? BLE next ; if not, skip to end MOV R1, #50 ; R1 = 1 STRB R1, [R2] ; G1 = 50 next |
signed char G1; if(G1>50){ G1 = 50; }
|
Program 7.5. A signed if-then structure LDRSB is a signed 8-bit load. BLE is a signed branch.
Notice that the C code for Program 7.2 looks similar to Program 7.4, and the C code for Program 7.3 looks similar to Program 7.5. This is because the compiler knows the type of variables G1 and G2; therefore, it knows whether to utilize unsigned or signed branches. Unfortunately, this similarity can be deceiving. When writing code whether it be assembly or C, you still need to keep track of whether your variables are signed or unsigned. Furthermore, when comparing two objects, they must have comparable types. E.g., “Which is bigger, 2 unsigned apples or –3 signed dollars?” The compiler does not seem to reject comparisons between signed and unsigned variables as an error. However, I recommend that you do not compare a signed variable to an unsigned variable. When comparing objects of different types, it is best to first convert both objects to the same format, and then perform the comparison. Conversely, we see that all numbers are converted to 32 bits before they are compared. This means there is no difficulty comparing variables of differing precisions: e.g., 8-bit, 16-bit, and 32-bit as long as both are signed or both are unsigned.
We can use the unconditional branch to add an else clause to any of the previous if then structures. A simple example of an unsigned conditional is illustrated in the Figure 7.4 and presented in Program 7.6. The first three lines test the condition G1>G2. If G1>G2, the software branches to high. Once at high, the software calls the isGreater subroutine then continues. Conversely, if G1≤G2, the software does not branch and the isLessEq subroutine is executed. After executing the isLessEq subroutine, there is an unconditional branch, so that only one and not both subroutines are called.
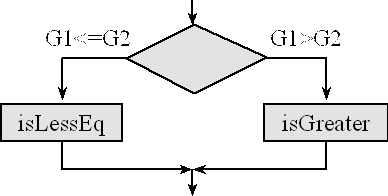
Figure 7.4. Flowchart of an if-then-else structure.
If-then-else - If
statements can be expanded by an "else" statement. If the condition is
false, the program will execute the statements under the "else"
statement. Choose two unsigned integers as variable a and b, press run
and follow the flow of the program and examine the output screen. You
can repeat the process with different variables.
variable a:
variable b:
| C Code | |
|---|---|
|
volatile unsigned long a; volatile unsigned long b; int main () { printf("Starting the Construct ...\n"); if (a<b){ printf("a is less than b\n"); } else { printf("a is not less than b\n"); } printf("Ending the Construct ...\n"); return 0; } |
|
| Output Screen | |
|
LDR R2, =G1 ; R2 = &G1 LDR R0, [R2] ; R0 = G1 LDR R2, =G2 ; R2 = &G2 LDR R1, [R2] ; R1 = G2 CMP R0, R1 ; is G1 > G2 ? BHI high ; if so, skip to high low BL isLessEq ; G1 <= G2 B next ; unconditional high BL isGreater ; G1 > G2 next |
unsigned long G1,G2; if(G1>G2){ isGreater(); } else{ isLessEq(); } |
Program 7.6. An unsigned if-then-else structure (unsigned 32-bit).
The selection operator takes three input parameters and yields one output result. The format is
Expr1 ? Expr2 : Expr3
The first input parameter is an expression, Expr1, which yields a Boolean (0 for false, not zero for true). Expr2 and Expr3 return values that are regular numbers. The selection operator will return the result of Expr2 if the value of Expr1 is true, and will return the result of Expr3 if the value of Expr1 is false. The type of the expression is determined by the types of Expr2 and Expr3. If Expr2 and Expr3 have different types, then promotion is applied. The left and right side perform identical functions. If b is 1 set a equal to 10, otherwise set a to 1.
|
a = (b==1) ? 10 : 1; |
if(b==1) a=10; else a=1; |
A 3-wide median filter can be designed using if-else conditional statements.
short
Median(short u1,short u2,short u3){ short result;
if(u1>u2)
if(u2>u3) result=u2; //
u1>u2,u2>u3 u1>u2>u3
else
if(u1>u3) result=u3; //
u1>u2,u3>u2,u1>u3 u1>u3>u2
else result=u1; //
u1>u2,u3>u2,u3>u1 u3>u1>u2
else
if(u3>u2) result=u2; //
u2>u1,u3>u2 u3>u2>u1
else
if(u1>u3) result=u1; //
u2>u1,u2>u3,u1>u3 u2>u1>u3
else result=u3; //
u2>u1,u2>u3,u3>u1 u2>u3>u1
return(result);
}
Program 7.7. A 3-wide median function.
: Assume you have a 32-bit unsigned global variable N. Write C code that changes N to 65535 if N is initially greater than 65535.
7.5.2. switch Statements
Switch statements provide a non-iterative choice between any number of paths based on specified conditions. They compare an expression to a set of constant values. Selected statements are then executed depending on which value, if any, matches the expression. The expression between the parentheses following switch is evaluated to a number and compared one by one to the explicit cases. Figure 7.5 draws a flowchart describes software that performs one output each time the function OneStep is called. The break causes execution to exit the switch statement. The default case is run if none of the explicit case statements match. The operation of the switch statement performs this list of actions:
If Last is equal to 10, then theNext is set to 9.
If Last is equal to 9, then theNext is set to 5.
If Last is equal to 5, then theNext is set to 6.
If Last is equal to 6, then theNext is set to 10.
If Last is not equal any of the above, then theNext is set to 10.
When using break, only the first matching case will be invoked. In other words, once a match is found, no other tests are performed. The body of the switch is not a normal compound statement since local declarations are not allowed in it or in subordinate blocks.
Assume the output port is connected to a stepper motor, and the motor has 24 steps per rotation. Calling OneStep will cause the motor to rotate by exactly 15 degrees. 15 degrees is 360 degrees divided by 24.
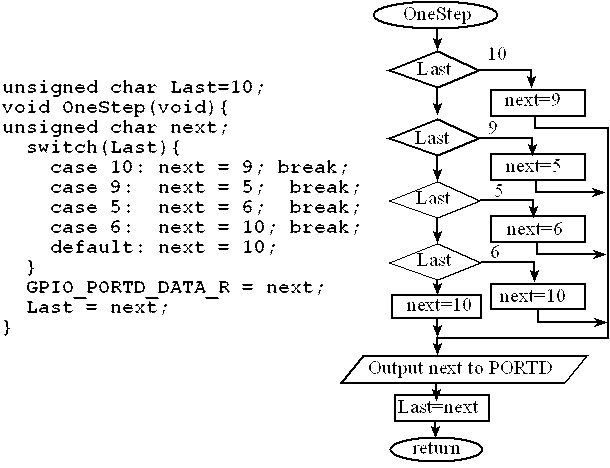
Figure 7.5. The switch statement is used to make multiple comparisons.
Program 7.8 converts an ASCII character to the equivalent decimal value. This example of a switch statement shows that the multiple tests can be performed for the same condition.
unsigned char Convert(unsigned char letter){
unsigned char digit;
switch (letter) {
case 'A':
case 'B':
case 'C':
case 'D':
case 'E':
case 'F':
digit = letter+10-'A'; break;
case 'a':
case 'b':
case 'c':
case 'd':
case 'e':
case 'f':
digit = letter+10-'a'; break;
default:
digit = letter-'0';
}
return digit;
}
Program 7.8. A switch statement is used to convert an ASCII character to numeric value.
: Write a C function that converts lower case ASCII to uppercase. If the input is between ‘a’ to ‘z’, then the output equals the input minus -0x20. If the input is not between ‘a’ to ‘z’, then the output equals the input.
7.5.3. While Loops
Quite often the microcomputer is asked to wait for events or to search for objects. Both of these operations are solved using the while or do-while structure. A simple example of while loop is illustrated in the Figure 7.6 and presented in Program 7.9. Assume Port A bit 3 is an input. The operation is defined by the C code
while(GPIO_PORTA_DATA_R&0x08){Body();}
specifies the function Body() will be executed over and over as long as Port A bit 3 is high. .
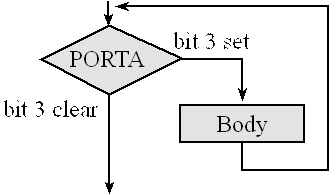
Figure 7.6. Flowchart of a while structure. Execute Body() over and over bit 3 of G1 is high.
Program 7.9 begins with a test of Port A bit 3. If bit 3 is low then the body of the while loop is skipped. The unconditional branch (B loop) after the body causes Port A bit 3 to be tested each time through the loop. In this way, the body is executed repeatedly until Port A bit 3 is low.
|
LDR R4, =GPIO_PORTA_DATA_R loop LDR R0, [R4] ; R0 = Port A AND R0, #0x08 ; test bit 3 BEQ next ; if so, quit BL Body ; body of the loop B loop next |
unsigned long G1,G2;
while(GPIO_PORTA_DATA_R&0x08){ Body(); } |
Program 7.9. A while loop structure.
Observation: The body of a while loop may execute zero or more times, but the body of a do-while loop is executed at least once.
One of the conventions when writing assembly is whether or not subroutines should save registers. According to AAPCS, we will allow subroutines to freely modify R0–R3 and R12. Conversely, if a subroutine wishes to use R4 through R11, it will preserve the values using the stack. Similarly, if the subroutine wishes to use LR (e.g., to call another subroutine) it must save and restore LR. This means address pointers R4 and R5 only need to be set once in Program 7.9, because we can assume that the call to Body() will not corrupt them. However, since the variables themselves are held in RAM and may therefore be changed by some other piece of code, it does make sense to reload the values of the variables each time through the loop.
Assume you have a 16-bit unsigned global variable N. Write C code that calls the function body over and over as long as bit 0 of N is a 1.
The
while loop - The
statements inside a while statement, will continuously be executed if
the while condition is true. If the condition is/becomes false, the
program will skip the loop and continue with the execution of the
remaining statements. Choose an unsigned integer less than 100000 as
variable a, press run and follow the flow of the program and examine
the output screen. The loop continuously divides the variable a by 10
and outputs the result. You can repeat the process with different
variables.
variable a:
| C Code | |
|---|---|
|
volatile unsigned long a; // a is always less than 100000 int main () { printf("Starting the loop ..., a = %d\n",a); while (a>0){ a = (a/10); printf("current a = %d\n",a); } printf("Ending the loop ...\n"); return 0; } |
|
| Output Screen | |
7.5.4. Do-while Loops
A do-while loop performs the body first, and the test for completion second. It will execute the body at least once. Assume PF1 and PA5 are definitions of I/O pins using bit-specific addressing. Program 7.10 will toggle the output PF1 as long as input PA5 is low.
|
LDR R1, =PF1 ; R1 = &PF1 LDR R5, =PA5 ; R5 = &PA5 loop LDR R0, [R1] EOR R0, #2 ; toggle bit 1 STR R0, [R1] LDR R2, [R5] ; R2 = PA5 ANDS R2, #0x20 ; bit 5 set? BEQ loop ; spin while low next |
// toggle PF1 while PA5 low do{ PF1 = PF1^0x02; } while((PA5&0x20)==0); |
Program 7.10. A do-while loop structure.
Assume PF4 PF3 and PF0 are bit-specific addresses for Port F pins 4, 3, 0 respectively. PF3 is an output, and PF4 and PF0 are inputs. Toggle PF3 once, and then keep toggling PF3 as long as both PF4 and PF0 are high.
The
do-while loop -
The statements inside a do-while statement will always be executed
once, and will continuously be executed if the while condition is true.
If the condition becomes false, the program will skip the loop and
continue with the execution of the remaining statements. Choose an
unsigned integers less than 100000 as variable a, press run and follow
the flow of the program and examine the output screen. The loop
continuously divides the variable a by 10 and outputs the result. You
can repeat the process with different variables.
variable a:
| C Code | |
|---|---|
|
volatile unsigned long a; int main () { printf("Starting the loop ..., a = %d\n",a); do { a = (a/10); printf("current a = %d\n",a); } while (a>0); printf("Ending the loop ...\n"); return 0; } |
|
| Output Screen | |
7.5.5. For Loops
A for-loop control structure is a special case of the while loop. For loops can iterate up or down. To show the similarity between the while loop and for loop these two C functions are identical. The <init> code is executed once. The <test> code returns a true/false and is tested before each iteration. The <body> and <end> codes are executed each iteration.
|
<init>; while(<test>){ <body>; <end>; } |
for(<init>; <test>; <end>){ <body>; } |
For-loops are a convenient way to perform repetitive tasks. As an example, we write code that calls Process() 10 times. Two possible solutions are illustrated in Figure 7.7. The solution on the left starts at 0 and counts up to 10, while the solution on the right starts at 10 and counts down to 0. The first field is the initialization task (e.g., i=0) which is performed only once at the beginning of the for loop. The next field specifies the conditions with which to continue execution (e.g., i<10), that is, we check this condition before deciding to repeat the loop another time or not. If the condition evaluates to false we end the for loop, otherwise we continue another repetition before checking again. The last field is the operation to perform after each iteration/repetition (e.g., i++), this is is the update task that is performed each iteration before the condition is checked. Similar to a while loop, the test occurs before each execution of the body. The order is as follows: initialize->condition_check(is true)->body->update->condition_check(is true)->body->update...update->condition_check(is false)->end for loop.
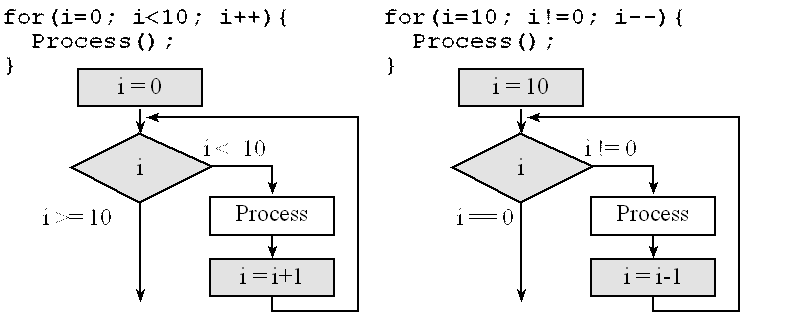
Figure 7.7. Two flowcharts of a for-loop structure.
The count-up implementation places the loop counter in the Register R4, as shown in Program 7.11. As mentioned earlier, we assume the subroutine Process preserves the value in R4.
|
MOV R4, #0 ; R4 = 0 loop CMP R4, #10 ; index >= 10? BHS done ; if so, skip to done BL Process ; process function ADD R4, R4, #1 ; R4 = R4 + 1 B loop done |
for(i=0; i<10; i++){ Process(); } |
Program 7.11. A simple for-loop.
If we assume the body will execute at least once, we can execute a little faster, as shown in Program 7.12, by counting down. Counting down is one instruction faster than counting up.
|
MOV R4, #10 ; R4 = 10 loop BL Process ; body SUBS R4, R4, #1 ; R4 = R4-1 BNE loop done |
MOV R4, #0 ; R4 = 0 loop BL Process ; body ADD R4, R4, #1 ; R4 = R4+1 CMP R4, #10 ; done? BLO loop ; if not,repeat |
The
for loop - A for
loop functionality is similar to a while loop, with automatic
initialization and update. It is usually used when the number of
iterations is known. One variable is used as a counter of iterations.
The first field of a "for loop" is the initialization, which is always
executed once. The second field is the condition to be checked. The
loop will continue being executed until the condition becomes false.
The third field (update) is executed at the end of each iteration and
is usually used for incrementing/decrementing the counter. Choose a
number less than 6 for variable a, and observe the flow of the
following program. You can repeat the process with different variables.
variable a:
| C Code | |
|---|---|
|
volatile long a; // a must be less than 6 in this example. int main () { int i; printf("Starting the loop ...\n"); for (i=0;i<a;i++){ printf("current i = %d\n",i); } printf("Ending the loop ...\n"); return 0; } |
|
| Output Screen | |
Program 7.12. Optimized for-loops.
Assume PF2 is a bit-specific address for Port F pin 2, and assume PF2 is an output. Write a C function that toggles PF2 one million times.
Functional debugging involves the verification of input/output parameters. Functional debugging is a static process where inputs are supplied, the system is run, and the outputs are compared against the expected results. Four methods of functional debugging are presented in this section, and two more functional debugging methods are presented in the next chapter after indexed addressing mode is presented. There are two important aspects of debugging: control and observability. The first step of debugging is to stabilize the system. In the debugging context, we stabilize the problem by creating a test routine that fixes (or stabilizes) all the inputs. In this way, we can reproduce the exact inputs over and over again. Stabilization is an effective approach to debugging because we can control exactly what software is being executed. Once stabilized, if we modify the program, we are sure that the change in our outputs is a function of the modification we made in our software and not due to a change in the input parameters. When a system has a small number of possible inputs (e.g., less than a million), it makes sense to test them all. When the number of possible inputs is large we need to choose a set of inputs. There are many ways to make this choice. We can select values:
Near the extremes and in the middle
Most typical of how our clients will properly use the system
Most typical of how our clients will improperly attempt to use the system
That differ by one
You know your system will find difficult
Using a random number generator
To stabilize the system we define a fixed set of inputs to test, run the system on these inputs, and record the outputs. Debugging is a process of finding patterns in the differences between recorded behavior and expected results. The advantage of modular programming is that we can perform modular debugging. We make a list of modules that might be causing the bug. We can then create new test routines to stabilize these modules and debug them one at a time. Unfortunately, sometimes all the modules seem to work, but the combination of modules does not. In this case we study the interfaces between the modules, looking for intended and unintended (e.g., unfriendly code) interactions.
Many debuggers allow you to set the program counter to a specific address then execute one instruction at a time. The debugger provides three stepping commands Step, StepOver and StepOut commands. Step is the usual execute one assembly instruction. However, when debugging C we can also execute one line of C. StepOver will execute one assembly instruction, unless that instruction is a subroutine call, in which case the debugger will execute the entire subroutine and stop at the instruction following the subroutine call. StepOut assumes the execution has already entered a subroutine, and will finish execution of the subroutine and stop at the instruction following the subroutine call.
A breakpoint is a mechanism to tag places in our software, which when executed will cause the software to stop. Normally, you can break on any line of your program.
One of the problems with breakpoints is that sometimes we have to observe many breakpoints before the error occurs. One way to deal with this problem is the conditional breakpoint. To illustrate the implementation of conditional breakpoints, add a global variable called Count and initialize it to 32 in the initialization ritual. Add the following conditional breakpoint to the appropriate location in your software. Using the debugger, we set a regular breakpoint at bkpt. We run the system again (you can change the 32 to match the situation that causes the error.)
|
PUSH {R1, R2} ; save R1 and R2 LDR R2, =Count ; R2 = Count LDR R1, [R2] ; R1 = Count SUBS R1, R1, #1 ; Count = Count – 1 STR R1, [R2] ; store to Count BNE DEBUG_skip ; if Count != 0, skip DEBUG_bkpt NOP ; put breakpoint here DEBUG_skip POP {R1, R2} ; restore R1 and R2 |
if(--Count==0) bkpt |
Notice that the breakpoint occurs only on the 32nd time the break is encountered. Any appropriate condition can be substituted. Most modern debuggers allow you to set breakpoints that will trigger on a count. However, this method allows flexibility of letting you choose the exact conditions that cause the break.
The use of print statements is a popular and effective means for functional debugging. One difficulty with print statements in embedded systems is that a standard “printer” may not be available. Another problem with printing is that most embedded systems involve time-dependent interactions with its external environment. The print statement itself may be so slow, that the debugging process itself causes the system to fail. In this regard, the print statement is intrusive. Therefore, throughout this book we will utilize debugging methods that do not rely on the availability of a standard output device.
Say, we are shipwrecked on an island and we want to send an SOS to aircraft and other ships passing by to get their attention. We have a LaunchPad and a battery that we can use to design a solution. Program 7.2 shows the solution developed in the videos.
Video 7.2. Pseudocode and Flowchart
// 0.Documentation Section
// C7_SOS, main.c
// Runs on LM4F120 or TM4C123 LaunchPad
// Input from PF4(SW1),PF0(SW2), output to PF3 (Green LED)
// Pressing SW1 starts SOS (Green LED flashes SOS).
// S: Toggle light 3 times with 1/2 sec gap between ON..1/2sec..OFF
// O: Toggle light 3 times with 2 sec gap between ON..2sec..OFF
// S: Toggle light 3 times with 1/2 sec gap between ON..1/2sec..OFF
// 5 second delay between SOS
// Pressing SW2 stops SOS
// Authors: Daniel Valvano, Jonathan Valvano and Ramesh Yerraballi
// Date: July 15, 2013
// 1. Pre-processor Directives Section
// Constant declarations to access port registers using
// symbolic names instead of addresses
#define GPIO_PORTF_DATA_R (*((volatile unsigned long *)0x400253FC))
#define GPIO_PORTF_DIR_R (*((volatile unsigned long *)0x40025400))
#define GPIO_PORTF_AFSEL_R (*((volatile unsigned long *)0x40025420))
#define GPIO_PORTF_PUR_R (*((volatile unsigned long *)0x40025510))
#define GPIO_PORTF_DEN_R (*((volatile unsigned long *)0x4002551C))
#define GPIO_PORTF_LOCK_R (*((volatile unsigned long *)0x40025520))
#define GPIO_PORTF_CR_R (*((volatile unsigned long *)0x40025524))
#define GPIO_PORTF_AMSEL_R (*((volatile unsigned long *)0x40025528))
#define GPIO_PORTF_PCTL_R (*((volatile unsigned long *)0x4002552C))
#define SYSCTL_RCGC2_R (*((volatile unsigned long *)0x400FE108))
// 2. Declarations Section
// Global Variables
unsigned long SW1; // input from PF4
unsigned long SW2; // input from PF0
// Function Prototypes
void PortF_Init(void);
void FlashSOS(void);
void delay(unsigned long halfsecs);
// 3. Subroutines Section
// MAIN: Mandatory for a C Program to be executable
int main(void){
PortF_Init(); // Init port PF4 PF2 PF0
while(1){
do{
SW1 = GPIO_PORTF_DATA_R&0x10; // PF4 into SW1
}while(SW1 == 0x10);
do{
FlashSOS();
SW2 = GPIO_PORTF_DATA_R&0x01; // PF0 into SW2
}while(SW2 == 0x01);
}
}
// Subroutine to initialize port F pins for input and output
// PF4 is input SW1 and PF2 is output Blue LED
// Inputs: None
// Outputs: None
// Notes: ...
void PortF_Init(void){ volatile unsigned long delay;
SYSCTL_RCGC2_R |= 0x00000020; // 1) F clock
delay = SYSCTL_RCGC2_R; // delay
GPIO_PORTF_LOCK_R = 0x4C4F434B; // 2) unlock PortF PF0
GPIO_PORTF_CR_R |= 0x1F; // allow changes to PF4-0
GPIO_PORTF_AMSEL_R &= 0x00; // 3) disable analog function
GPIO_PORTF_PCTL_R &= 0x00000000; // 4) GPIO clear bit PCTL
GPIO_PORTF_DIR_R &= ~0x11; // 5.1) PF4,PF0 input,
GPIO_PORTF_DIR_R |= 0x08; // 5.2) PF3 output
GPIO_PORTF_AFSEL_R &= 0x00; // 6) no alternate function
GPIO_PORTF_PUR_R |= 0x11; // enable pullup resistors on PF4,PF0
GPIO_PORTF_DEN_R |= 0x1F; // 7) enable digital pins PF4-PF0
}
// Color LED(s) PortF
// dark --- 0
// red R-- 0x02
// blue --B 0x04
// green -G- 0x08
// yellow RG- 0x0A
// sky blue -GB 0x0C
// white RGB 0x0E
// Subroutine to Flash a green LED SOS once
// PF3 is green LED: SOS
// S: Toggle light 3 times with 1/2 sec gap between ON..1/2sec..OFF
// O: Toggle light 3 times with 2 sec gap between ON..2sec..OFF
// S: Toggle light 3 times with 1/2 sec gap between ON..1/2sec..OFF
// Inputs: None
// Outputs: None
// Notes: ...
void FlashSOS(void){
//S
GPIO_PORTF_DATA_R |= 0x08; delay(1);
GPIO_PORTF_DATA_R &= ~0x08; delay(1);
GPIO_PORTF_DATA_R |= 0x08; delay(1);
GPIO_PORTF_DATA_R &= ~0x08; delay(1);
GPIO_PORTF_DATA_R |= 0x08; delay(1);
GPIO_PORTF_DATA_R &= ~0x08; delay(1);
//O
GPIO_PORTF_DATA_R |= 0x08; delay(4);
GPIO_PORTF_DATA_R &= ~0x08;delay(4);
GPIO_PORTF_DATA_R |= 0x08; delay(4);
GPIO_PORTF_DATA_R &= ~0x08;delay(4);
GPIO_PORTF_DATA_R |= 0x08; delay(4);
GPIO_PORTF_DATA_R &= ~0x08;delay(4);
//S
GPIO_PORTF_DATA_R |= 0x08; delay(1);
GPIO_PORTF_DATA_R &= ~0x08;delay(1);
GPIO_PORTF_DATA_R |= 0x08; delay(1);
GPIO_PORTF_DATA_R &= ~0x08;delay(1);
GPIO_PORTF_DATA_R |= 0x08; delay(1);
GPIO_PORTF_DATA_R &= ~0x08;delay(1);
delay(10); // Delay for 5 secs in between flashes
}
// Subroutine to delay in units of half seconds
// We will make a precise estimate later:
// For now we assume it takes 1/2 sec to count down
// from 2,000,000 down to zero
// Inputs: Number of half seconds to delay
// Outputs: None
// Notes: ...
void delay(unsigned long halfsecs){
unsigned long count;
while(halfsecs > 0 ) { // repeat while still halfsecs to delay
count = 1538460;
// originally count was 400000, which took 0.13 sec to complete
// later we change it to 400000*0.5/0.13=1538460 that it takes 0.5 sec
while (count > 0) {
count--;
} // This while loop takes approximately 3 cycles
halfsecs--;
}
}
Program 7.13. Software solution that implements the rescue device (C7_SOS).
Reprinted with approval from Embedded Systems: Introduction to ARM Cortex-M Microcontrollers, 2014, ISBN: 978-1477508992, http://users.ece.utexas.edu/~valvano/arm/outline1.htm
