![]()
Chapter 3: Numbers, Characters and Strings
What's in Chapter 3?
How are numbers represented on the
computer
8-bit unsigned numbers
8-bit signed numbers
16-bit unsigned numbers
16-bit signed numbers
Big and little endian
Boolean (true/false)
Decimal numbers
Hexadecimal numbers
Octal numbers
Characters
Strings
Escape sequences
This chapter defines the various data types supported by the compiler. Since the objective of most computer systems is to process data, it is important to understand how data is stored and interpreted by the software. We define a literal as the direct specification of the number, character, or string. E.g.,
100
'a' "Hello World"
are examples of a number literal, a character literal and a string literal respectively. We will discuss the way data are stored on the computer as well as the C syntax for creating the literals. The Imagecraft and Metrowerks compilers recognize three types of literals (numeric, character, string). Numbers can be written in three bases (decimal, octal, and hexadecimal). Although the programmer can choose to specify numbers in these three bases, once loaded into the computer, the all numbers are stored and processed as unsigned or signed binary. Although C does not support the binary literals, if you wanted to specify a binary number, you should have no trouble using either the octal or hexadecimal format.
Numbers are stored on the computer in binary form. In other words, information is encoded as a sequence of 1’s and 0’s. On most computers, the memory is organized into 8-bit bytes. This means each 8-bit byte stored in memory will have a separate address. Precision is the number of distinct or different values. We express precision in alternatives, decimal digits, bytes, or binary bits. Alternatives are defined as the total number of possibilities. For example, an 8-bit number scheme can represent 256 different numbers. An 8-bit digital to analog converter can generate 256 different analog outputs. An 8-bit analog to digital converter (ADC) can measure 256 different analog inputs. We use the expression 4½ decimal digits to mean about 20,000 alternatives and the expression 4¾ decimal digits to mean more than 20,000 alternatives but less than 100,000 alternatives. The ½ decimal digit means twice the number of alternatives or one additional binary bit. For example, a voltmeter with a range of 0.00 to 9.99V has a three decimal digit precision. Let the operation [[x]] be the greatest integer of x. E.g., [[2.1]] is rounded up to 3. Tables 3.1a and 3.1b illustrate various representations of precision.
|
Binary bits |
Bytes |
Alternatives |
|
8 |
1 |
256 |
|
10 |
|
1024 |
|
12 |
|
4096 |
|
16 |
2 |
65536 |
|
20 |
|
1,048,576 |
|
24 |
3 |
16,777,216 |
|
30 |
|
1,073,741,824 |
|
32 |
4 |
4,294,967,296 |
|
n |
[[n/8]] |
2n |
|
Decimal digits |
Alternatives |
|
3 |
1000 |
|
3½ |
2000 |
|
3¾ |
4000 |
|
4 |
10000 |
|
4½ |
20000 |
|
4¾ |
40000 |
|
5 |
100000 |
|
n |
10n |
Observation: A good rule of thumb to remember is 210•n is about 103•n.
For large numbers we use abbreviations, as shown in the following table. For example, 16K means 16*1024 which equals 16384. Computer engineers use the same symbols as other scientists, but with slightly different values.
| abbreviation | pronunciation | Computer Engineering Value | Scientific Value |
| K | "kay" | 210 1024 | 103 |
| M | "meg" | 220 1,048,576 | 106 |
| G | "gig" | 230 1,073,741,824 | 109 |
| T | "tera" | 240 1,099,511,627,776 | 1012 |
| P | "peta" | 250 1,125,899,906,843,624 | 1015 |
| E | "exa" | 260 1,152,921,504,606,846,976 | 1018 |
A byte contains 8 bits
![]()
where each bit b7,...,b0 is binary and has the value 1 or 0. We specify b7 as the most significant bit or MSB, and b0 as the least significant bit or LSB. If a byte is used to represent an unsigned number, then the value of the number is
N = 128•b7 + 64•b6 + 32•b5 + 16•b4 + 8•b3 + 4•b2 + 2•b1 + b0
There are 256 different unsigned 8-bit numbers. The smallest unsigned 8-bit number is 0 and the largest is 255. For example, 000010102 is 8+2 or 10. Other examples are shown in the following table.
| binary | hex | Calculation | decimal |
| 00000000 | 0x00 | 0 | |
| 01000001 | 0x41 | 64+1 | 65 |
| 00010110 | 0x16 | 16+4+2 | 22 |
| 10000111 | 0x87 | 128+4+2+1 | 135 |
| 11111111 | 0xFF | 128+64+32+16+8+4+2+1 | 255 |
The basis of a number system is a subset from which linear combinations of the basis elements can be used to construct the entire set. For the unsigned 8-bit number system, the basis is
{ 1, 2, 4, 8, 16, 32, 64, 128}
One way for us to convert a decimal number into binary is to use the basis elements. The overall approach is to start with the largest basis element and work towards the smallest. One by one we ask ourselves whether or not we need that basis element to create our number. If we do, then we set the corresponding bit in our binary result and subtract the basis element from our number. If we do not need it, then we clear the corresponding bit in our binary result. We will work through the algorithm with the example of converting 100 to 8 bit binary. We with the largest basis element (in this case 128) and ask whether or not we need to include it to make 100. Since our number is less than 128, we do not need it so bit 7 is zero. We go the next largest basis element, 64 and ask do we need it. We do need 64 to generate our 100, so bit 6 is one and subtract 100 minus 64 to get 36. Next we go the next basis element, 32 and ask do we need it. Again we do need 32 to generate our 36, so bit 5 is one and we subtract 36 minus 32 to get 4. Continuing along, we need basis element 4 but not 16 8 2 or 1, so bits 43210 are 00100 respectively. Putting it together we get 011001002 (which means 64+32+4).
Observation: If the least significant binary bit is zero, then the number is even.
Observation: If the right most n bits (least significant) are zero, then the number is divisible by 2n.
| Number | Basis | Need it | bit | Operation |
| 100 | 128 | no | bit7=0 | none |
| 100 | 64 | yes | bit6=1 | subtract 100-64 |
| 36 | 32 | yes | bit5=1 | subtract 36-32 |
| 4 | 16 | no | bit4=0 | none |
| 4 | 8 | no | bit3=0 | none |
| 4 | 4 | yes | bit2=1 | subtract 4-4 |
| 0 | 2 | no | bit1=0 | none |
| 0 | 1 | no | bit0=0 | none |
We define an unsigned 8-bit
number using the unsigned
char format. When a number is
stored into an unsigned char
it is converted to 8-bit unsigned value. For example
unsigned
char data; // 0 to 255
unsigned char function(unsigned char input){
data=input+1;
return data;}
If a byte is used to represent a signed 2’s complement number, then the value of the number is
N = -128•b7 + 64•b6 + 32•b5 + 16•b4 + 8•b3 + 4•b2 + 2•b1 + b0
There are also 256 different signed 8 bit numbers. The smallest signed 8-bit number is -128 and the largest is 127. For example, 100000102 is -128+2 or -126. Other examples are shown in the following table.
| binary | hex | Calculation | decimal |
| 00000000 | 0x00 | 0 | |
| 01000001 | 0x41 | 64+1 | 65 |
| 00010110 | 0x16 | 16+4+2 | 22 |
| 10000111 | 0x87 | -128+4+2+1 | -121 |
| 11111111 | 0xFF | -128+64+32+16+8+4+2+1 | -1 |
For the signed 8-bit number system the basis is
{ 1, 2, 4, 8, 16, 32, 64, -128}
Observation: The most significant bit in a 2’s complement signed number will specify the sign.
Notice that the same binary pattern of 111111112 could represent either 255 or -1. It is very important for the software developer to keep track of the number format. The computer can not determine whether the 8-bit number is signed or unsigned. You, as the programmer, will determine whether the number is signed or unsigned by the specific assembly instructions you select to operate on the number. Some operations like addition, subtraction, and shift left (multiply by 2) use the same hardware (instructions) for both unsigned and signed operations. On the other hand, multiply, divide, and shift right (divide by 2) require separate hardware (instruction) for unsigned and signed operations. The compiler will automatically choose the proper implementation.
It is always good programming practice to have clear understanding of the data type for each number, variable, parameter, etc. For some operations there is a difference between the signed and unsigned numbers while for others it does not matter.
| signed different from unsigned | signed same as unsigned | ||
| / % | division | + | addition |
| * | multiplication | - | subtraction |
| > | greater than | == | is equal to |
| < | less than | | | logical or |
| >= | greater than or equal to | & | logical and |
| <= | less than or equal to | ^ | logical exclusive or |
| >> | right shift | << | left shift |
The point is that care must be taken when dealing with a mixture of numbers of different sizes and types.
Similar to the unsigned algorithm, we can use the basis to convert a decimal number into signed binary. We will work through the algorithm with the example of converting -100 to 8-bit binary. We with the largest basis element (in this case -128) and decide do we need to include it to make -100. Yes (without -128, we would be unable to add the other basis elements together to get any negative result), so we set bit 7 and subtract the basis element from our value. Our new value is -100 minus -128, which is 28. We go the next largest basis element, 64 and ask do we need it. We do not need 64 to generate our 28, so bit6 is zero. Next we go the next basis element, 32 and ask do we need it. We do not need 32 to generate our 28, so bit5 is zero. Now we need the basis element 16, so we set bit4, and subtract 16 from our number 28 (28-16=12). Continuing along, we need basis elements 8 and 4 but not 2 1, so bits 3210 are 1100. Putting it together we get 100111002 (which means -128+16+8+4).
| Number | Basis | Need it | bit | Operation |
| -100 | -128 | yes | bit7=1 | subtract -100 - -128 |
| 28 | 64 | no | bit6=0 | none |
| 28 | 32 | no | bit5=0 | none |
| 28 | 16 | yes | bit4=1 | subtract 28-16 |
| 12 | 8 | yes | bit3=1 | subtract 12-8 |
| 4 | 4 | yes | bit2=1 | subtract 4-4 |
| 0 | 2 | no | bit1=0 | none |
| 0 | 1 | no | bit0=0 | none |
A second way to convert negative numbers into binary is to first convert them into unsigned binary, then do a 2’s complement negate. For example, we earlier found that +100 is 011001002. The 2’s complement negate is a two step process. First we do a logic complement (flip all bits) to get 100110112. Then add one to the result to get 100111002.
A third way to convert negative numbers into binary is to first subtract the number from 256, then convert the unsigned result to binary using the unsigned method. For example, to find -100, we subtract 256 minus 100 to get 156. Then we convert 156 to binary resulting in 100111002. This method works because in 8 bit binary math adding 256 to number does not change the value. E.g., 256-100 is the same value as -100.
Maintenance Tip: To improve the clarity of our software, always specify the format of your data (signed versus unsigned) when defining or accessing the data.
We define a signed 8-bit number
using the char
format. When a number is stored into a char
it is converted to 8-bit signed value. For example
char
data; // -128 to 127
char function(char input){
data=input+1;
return data;}
A halfword or double byte contains 16 bits. A word contains 32 bits.
![]()
where each bit b15,...,b0 is binary and has the value 1 or 0. If a word is used to represent an unsigned number, then the value of the number is
N = 32768•b15 + 16384•b14 + 8192•b13 + 4096•b12
+ 2048•b11 + 1024•b10 + 512•b9 + 256•b8
+ 128•b7 + 64•b6 + 32•b5 + 16•b4 + 8•b3 + 4•b2 + 2•b1 + b0
There are 65,536 different unsigned 16-bit numbers. The smallest unsigned 16-bit number is 0 and the largest is 65535. For example, 0010,0001,1000,01002 or 0x2184 is 8192+256+128+4 or 8580. Other examples are shown in the following table.
| binary | hex | Calculation | decimal |
| 0000,0000,0000,0000 | 0x0000 | 0 | |
| 0000,0100,0000,0001 | 0x0401 | 1024+1 | 1025 |
| 0000,1100,1010,0000 | 0x0CA0 | 2048+1024+128+32 | 3232 |
| 1000,1110,0000,0010 | 0x8E02 | 32768+2048+1024+512+2 | 36354 |
| 1111,1111,1111,1111 | 0xFFFF | 32768+16384+8192+4096+2048+1024 +512+256+128+64+32+16+8+4+2+1 | 65535 |
For the unsigned 16-bit number system the basis is
{ 1, 2, 4, 8, 16, 32, 64, 128, 256, 512, 1024, 2048, 4096, 8192, 16384, 32768}
If a word is used to represent a signed 2’s complement number, then the value of the number is
N = -32768•b15 + 16384•b14 + 8192•b13 + 4096•b12
+ 2048•b11 + 1024•b10 + 512•b9 + 256•b8
+ 128•b7 + 64•b6 + 32•b5 + 16•b4 + 8•b3 + 4•b2 + 2•b1 + b0
We define an unsigned 16-bit
number using the unsigned
short format. When a number
is stored into an unsigned
short it is converted to
16-bit unsigned value. For example
unsigned
short data; // 0 to 65535
unsigned short function(unsigned short input){
data=input+1;
return data;}
There are also 65,536 different signed 16-bit numbers. The smallest signed 16-bit number is -32768 and the largest is 32767. For example, 1101,0000,0000,01002 or 0xD004 is -32768+16384+4096+4 or -12284. Other examples are shown in the following table.
| binary | hex | Calculation | decimal |
| 0000,0000,0000,0000 | 0x0000 | 0 | |
| 0000,0100,0000,0001 | 0x0401 | 1024+1 | 1025 |
| 0000,1100,1010,0000 | 0x0CA0 | 2048+1024+128+32 | 3232 |
| 1000,0100,0000,0010 | 0x8402 | -32768+1024+2 | -31742 |
| 1111,1111,1111,1111 | 0xFFFF | -32768+16384+8192+4096+2048+1024 +512+256+128+64+32+16+8+4+2+1 | -1 |
For the signed 16-bit number system the basis is
{ 1, 2, 4, 8, 16, 32, 64, 128, 256, 512, 1024, 2048, 4096, 8192, 16384, -32768}
Maintenance Tip: To improve the quality of our software, we should always specify the precision of our data when defining or accessing the data.
We define a signed 16-bit
number using the short
format. When a number is stored into a short
it is converted to 16-bit signed value. For example
short
data; // -23768 to 32767
short function(short input){
data=input+1;
return data;}
When we store 16-bit data into memory it requires two bytes. Since the memory systems on most computers are byte addressable (a unique address for each byte), there are two possible ways to store in memory the two bytes that constitute the 16-bit data. Freescale microcomputers implement the big endian approach that stores the most significant part first. The ARM Cortex M processors implement the little endian approach that stores the least significant part first. Some ARM processors are biendian, because they can be configured to efficiently handle both big and little endian. For example, assume we wish to store the 16 bit number 1000 (0x03E8) at locations 0x50,0x51, then
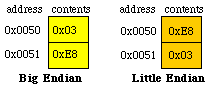
We also can use either the big or little endian approach when storing 32-bit numbers into memory that is byte (8-bit) addressable. If we wish to store the 32-bit number 0x12345678 at locations 0x50-0x53 then

In the above two examples we normally would not pick out individual bytes (e.g., the 0x12), but rather capture the entire multiple byte data as one nondivisable piece of information. On the other hand, if each byte in a multiple byte data structure is individually addressable, then both the big and little endian schemes store the data in first to last sequence. For example, if we wish to store the 4 ASCII characters ‘6811’ which is 0x36383131 at locations 0x50-0x53, then the ASCII ‘6’=0x36 comes first in both big and little endian schemes.

The term "Big Endian" comes from Jonathan Swift’s satire Gulliver’s Travels. In Swift’s book, a Big Endian refers to a person who cracks their egg on the big end. The Lilliputians considered the big endians as inferiors. The big endians fought a long and senseless war with the Lilliputians who insisted it was only proper to break an egg on the little end.
A boolean number is has two states. The two values could represent the logical true or false. The positive logic representation defines true as a 1 or high, and false as a 0 or low. If you were controlling a motor, light, heater or air conditioner the boolean could mean on or off. In communication systems, we represent the information as a sequence of booleans: mark or space. For black or white graphic displays we use booleans to specify the state of each pixel. The most efficient storage of booleans on a computer is to map each boolean into one memory bit. In this way, we could pack 8 booleans into each byte. If we have just one boolean to store in memory, out of convenience we allocate an entire byte or word for it. Most C compilers including Keil uVision define:
False be all zeros, and
True be any nonzero value.
Many programmers add the following macros
#define
TRUE 1
#define FALSE 0
Decimal numbers are written as a sequence of decimal digits (0 through 9). The number may be preceded by a plus or minus sign or followed by a Lor U. Lower case l or u could also be used. The minus sign gives the number a negative value, otherwise it is positive. The plus sign is optional for positive values. Unsigned 16-bit numbers between 32768 and 65535 should be followed by U. You can place a L at the end of the number to signify it to be a 32-bit signed number. The range of a decimal number depends on the data type as shown in the following table. On the Keil uVision compiler, the char data type may be signed or unsigned depending on a compiler option.
| type | range | precision | examples |
| unsigned char | 0 to 255 | 8 bits | 0 10 123 |
| char | -128 to 127 | 8 bits | -123 0 10 +10 |
| unsigned int | 0 to 4294967295 | 32 bits | 0 2000 2000 50000000L |
| int | -2147483648 to 2147483647 | 16 bits | -1000 0 1000 +20000 |
| unsigned short | 0 to 65535U | 16 bits | 0 2000 2000U 50000U |
| short | -32768 to 32767 | 16 bits | -1000 0 1000 +20000 |
| long | -2147483648 to 2147483647 | 32 bits | -123456L 0L 1234567L |
| unsigned long | 0 to 4294967295 | 32 bits | 0L 12345678L |
Because the ARM Cortex microcomputers are most efficient for 32 bit-data (and not 64-bit data), the unsigned int and int data types are 32 bits. On the other hand, on a 9S16-based machine, the unsigned int and int data types are 16 bits. In order to make your software more compatible with other machines, it is preferable to use the short type when needing 16-bit data and the long type for 32-bit data.
| type | 6811/6812 | Cortex M |
| unsigned char | 8 bits | 8 bits |
| char | 8 bits | 8 bits |
| unsigned int | 16 bits | 32 bits |
| int | 16 bits | 32 bits |
| unsigned short | 16 bits | 16 bits |
| short | 16 bits | 16 bits |
| long | 32 bits | 32 bits |
Since the Cortex M microcomputers do not have direct support of 64-bit numbers, the use of long long data types should be minimized. On the other hand, a careful observation of the code generated yields the fact that these compilers are more efficient with 32-bit numbers than with 8-bit or 16-bit numbers.
Decimal numbers are reduced to their two's complement or unsigned binary equivalent and stored as 8/16/32-bit binary values.
The manner in which decimal literals are treated depends on the context. For example
short
I;
unsigned short J;
char K;
unsigned char L;
long M;
void main(void){
I=97; /*
16 bits 0x0061 */
J=97; /*
16 bits 0x0061 */
K=97; /*
8 bits 0x61 */
L=97; /*
8 bits 0x61 */
M=97; /*
32 bits 0x00000061 */}
If a sequence of digits begins with a leading 0(zero) it is interpreted as an octal value. There are only eight octal digits, 0 through 7. As with decimal numbers, octal numbers are converted to their binary equivalent in 8-bit or 16-bit words. The range of an octal number depends on the data type as shown in the following table.
| type | range | precision | examples |
| unsigned char | 0 to 0377 | 8 bits | 0 010 0123 |
| char | -0200 to 0177 | 8 bits | -0123 0 010 +010 |
| unsigned short | 0 to 0177777 | 16 bits | 0 02000 0150000U |
| short | -0100000 to 077777 | 16 bits | -01000 0 01000 +020000 |
| long | -020000000000 to 017777777777 | 32 bits | -01234567L 0L 01234567L |
Notice that the octal values 0 through 07 are equivalent to the decimal values 0 through 7. One of the advantages of this format is that it is very easy to convert back and forth between octal and binary. Each octal digit maps directly to/from 3 binary digits.
The hexadecimal number system uses base 16 as opposed to our regular decimal number system that uses base 10. Like the octal format, the hexadecimal format is also a convenient mechanism for us humans to represent binary information, because it is extremely simple for us to convert back and forth between binary and hexadecimal. A nibble is defined as 4 binary bits. Each value of the 4-bit nibble is mapped into a unique hex digit.
| Hex Digit | Decimal Value | Binary Value |
| 0 | 0 | 0000 |
| 1 | 1 | 0001 |
| 2 | 2 | 0010 |
| 3 | 3 | 0011 |
| 4 | 4 | 0100 |
| 5 | 5 | 0101 |
| 6 | 6 | 0110 |
| 7 | 7 | 0111 |
| 8 | 8 | 1000 |
| 9 | 9 | 1001 |
| A or a | 10 | 1010 |
| B or b | 11 | 1011 |
| C or c | 12 | 1100 |
| D or d | 13 | 1101 |
| E or e | 14 | 1110 |
| F or f | 15 | 1111 |
Computer programming environments use a wide variety of symbolic notations to specify the numbers in various bases. The following table illustrates various formats for numbers
| environment | binary format | hexadecimal format | decimal format |
| Freescale assembly language | %01111010 | $7A | 122 |
| Intel and TI assembly language | 01111010B | 7AH | 122 |
| C language | - | 0x7A | 122 |
To convert from binary to hexadecimal we can:
1) divide the binary number
into right justified nibbles;
2) convert each nibble into its corresponding hexadecimal digit.
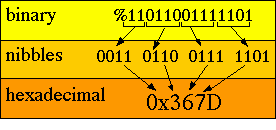
To convert from hexadecimal to binary we can:
1) convert each hexadecimal
digit into its corresponding 4 bit binary nibble;
2) combine the nibbles into a single binary number.
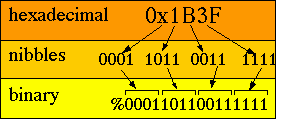
If a sequence of digits begins with 0x or 0X then it is taken as a hexadecimal value. In this case the word digits refers to hexadecimal digits (0 through F). As with decimal numbers, hexadecimal numbers are converted to their binary equivalent in 8-bit bytes or16-bit words. The range of a hexadecimal number depends on the data type as shown in the following table.
| type | range | precision | examples |
| unsigned char | 0x00 to 0xFF | 8 bits | 0x01 0x3a 0xB3 |
| char | -0x80 to 0x7F | 8 bits | -0x01 0x3a -0x7B |
| unsigned short | 0x0000 to 0xFFFF | 16 bits | 0x22 0Xabcd 0xF0A6 |
| short | -0x8000 to 0x7FFF | 16 bits | -0x1234 0x0 +0x7abc |
| long | -0x80000000 to 0x7FFFFFFF | 32 bits | -0x1234567 0xABCDEF |
Character literals consist of one or two characters surrounded by apostrophes. The manner in which character literals are treated depends on the context. For example
short
I;
unsigned short J;
char K;
unsigned char L;
long M;
void main(void){
I='a'; /*
16 bits 0x0061 */
J='a'; /*
16 bits 0x0061 */
K='a'; /*
8 bits 0x61 */
L='a'; /*
8 bits 0x61 */
M='a'; /*
32 bits 0x00000061 */}
All standard ASCII characters are positive because the high-order bit is zero. In most cases it doesn't matter if we declare character variables as signed or unsigned. On the other hand, we have seen earlier that the compiler treats signed and unsigned numbers differently. Unless a character variable is specifically declared to be unsigned, its high-order bit will be taken as a sign bit. Therefore, we should not expect a character variable, which is not declared unsigned, to compare equal to the same character literal if the high-order bit is set. For more on this see Chapter 4 on Variables.
Strictly speaking, C does not recognize character strings, but it does recognize arrays of characters and provides a way to write character arrays, which we call strings. Surrounding a character sequence with quotation marks, e.g., "Jon", sets up an array of characters and generates the address of the array. In other words, at the point in a program where it appears, a string literal produces the address of the specified array of character literals. The array itself is located elsewhere. Metrowerks will place strings into the text area. I.e., the string literals are considered constant and will be defined in the ROM of an embedded system. This is very important to remember. Notice that this differs from a character literal which generates the value of the literal directly. Just to be sure that this distinct feature of the C language is not overlooked, consider the following example:
char
*pt;
extern void Foo(char *p);
void main(void){
pt="Jon"; /* pointer
to the string */
Foo(pt); /* passes the pointer
not the data itself */
}
Note that the pointer, pt,
is allocated in RAM and the string is stored in ROM. The
assignment statement pt="Jon";
copies the address not the data. First, the address of the string
is assigned to the character
pointer pt
(Keil uVision uses the 32-bit
Register R0 for the first parameter). Unlike other languages, the
string
itself is not assigned to pt,
only its address is. After all, pt
is a 32-bit object and, therefore, cannot hold the string itself.
Since strings may contain as few as one or two characters, they provide
an alternative way of writing character literals in situations where
the address, rather than the character itself, is needed.
It is a convention in C to identify the end of a character string with a null (zero) character. Therefore, C compilers automatically suffix character strings with such a terminator. Thus, the string "Jon" sets up an array of four characters ('J', 'o', 'n', and zero) and generates the address of the first character, for use by the program.
Remember that 'A' is different from "A", consider the following example:
char
letter,*pt;
void main(void){
pt="A"; /*
pointer to the string */
letter='A'; /*
the data itself ('A' ASCII 65=$41) */
}
Sometimes it is desirable to code nongraphic characters in a character or string literal. This can be done by using an escape sequence--a sequence of two or more characters in which the first (escape) character changes the meaning of the following character(s). When this is done the entire sequence generates only one character. C uses the backslash (\) for the escape character. The following escape sequences are recognized by the Metrowerks compiler:
| sequence | name | value |
| \n | newline, linefeed | 0x0A = 10 |
| \t | tab | 0x09 = 9 |
| \b | backspace | 0x08 = 8 |
| \f | form feed | 0x0C = 12 |
| \a | bell | 0x07 = 7 |
| \r | return | 0x0D = 13 |
| \v | vertical tab | 0x0B = 11 |
| \0 | null | 0x00 = 0 |
| \" | ASCII quote | 0x22 = 34 |
| \\ | ASCII back slash | 0x5C = 92 |
| \' | ASCII single quote | 0x27 = 39 |
Other nonprinting characters can also be defined using the \ooo octal format. The digits ooo can define any 8-bit octal number. The following three lines are equivalent:
printf("\tJon\n");
printf("\11Jon\12");
printf("\011Jon\012");
The term newline
refers to a single character which, when written to an output device,
starts a new line. Some hardware devices use the ASCII carriage return
(13) as the newline character while others use the ASCII line feed
(10). It really doesn't matter which is the case as long as we write \n
in our programs. Avoid using the ASCII value directly since that could
produce compatibility problems between different compilers.
There is one other type of escape sequence: anything undefined. If the backslash is followed by any character other than the ones described above, then the backslash is ignored and the following character is taken literally. So the way to code the backslash is by writing a pair of backslashes and the way to code an apostrophe or a quote is by writing \' or \" respectively.
Go to Chapter 4 on Variables Return to Table of Contents