Chapter
1: Introduction to Embedded Systems
Jonathan Valvano and Ramesh Yerraballi
This chapter covers the basic foundation concepts needed to build upon in this course. Specifically we will look at embedded systems, number representation, digital logic, embedded system components, and computer architecture: the Central Processing Unit (Arithmetic Logic Unit, Control Unit and Registers), the memory and the Instruction Set Architecture (ISA).
Table of Contents:
- 1.1. Embedded Systems
- 1.2. Binary Information Implemented with MOS transistors
- 1.3.
Numbers
- 1.4. Introduction to Computers
- 1.5.
Memory
- 1.6.
Pseudo-ops
- 1.7.
Instruction Set Architecture
- 1.8.
Flowcharts, Structured Programming and Conditional Statements
- 1.9.
Stack and Functions
- 1.10.
Introduction to data structures
- 1.11.
Lab 1. Introduction to Cortex M Assembly
Video 1.0. Introduction, Examples of Embedded Systems
Reference material relative to this chapter:
- Digital logic
- Embedded Software in C for an ARM Cortex M
- MSPM0G3507 LaunchPad Users Manual
- ECE319K Book appendix 3 (ECE319K book)
- ArmClang_Reference_Guide (ARM)
- ARMv6-M Architecture Reference Manual (ARM)
- The ARM Cortex-M Technical Reference Manual (ARM)
1.1. Embedded Systems
To better understand the expression embedded microcomputer system, consider each word separately. In this context, the word “embedded” means hidden inside so one can’t see it. The term “micro” means small, and a “computer” contains a processor, memory, and a means to exchange data with the external world. The word “system” means multiple components interfaced together for a common purpose. Systems have structure, behavior, and interconnectivity operating in a framework bound by rules and regulations. Another name for embedded systems is Cyber-Physical Systems, introduced in 2006 by Helen Gill of the National Science Foundation, because these systems combine the intelligence of a computer with the physical objects of our world. As shown in Figure 1.1.1, the term embedded microcomputer system refers to a device that contains one or more microcomputers inside. Microcontrollers, which are complete computers incorporating the processor, RAM, ROM and I/O ports into a single package, are often employed in an embedded system because of their low cost, small size, and low power requirements.
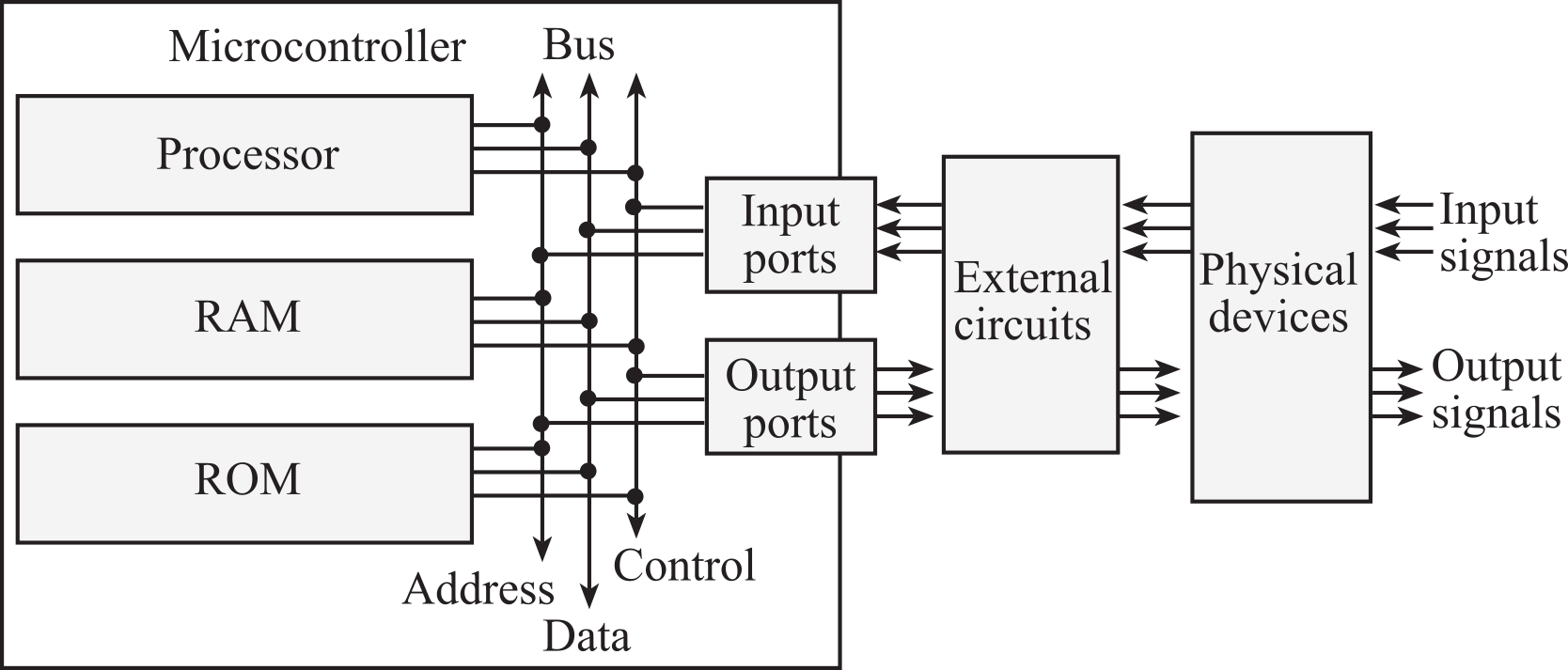
Figure 1.1.1. An embedded system includes a microcomputer interfaced to external physical devices.
An embedded system includes a microcomputer with mechanical, chemical, and electrical devices attached to it, programmed for a specific dedicated purpose, and packaged up as a complete system. Any electrical, mechanical, or chemical system that involves inputs, decisions, calculations, analyses, and outputs is a candidate for implementation as an embedded system. Electrical, mechanical, and chemical sensors collect information. Electronic interfaces convert the sensor signals into a form acceptable for the microcomputer. For example, a tachometer is a sensor that measures the revolutions per second of a rotating shaft. Microcomputer software performs the necessary decisions, calculations, and analyses. Additional interface electronics convert the microcomputer outputs into the necessary form. Actuators can be used to create mechanical or chemical outputs. For example, an electrical motor converts electrical power into mechanical power.
If the embedded system is connected to the
internet, it is classified as an Internet of Things (IoT).
Video
1.1.1. Components of an embedded system
Figure 1.1.2. Embedded systems have computers hidden inside.
: What is an embedded system?
1.2. Binary Information Implemented with MOS transistors
Information is stored on the computer in binary form. A binary bit can exist in one of two possible states. In positive logic, the higher voltage is called the ‘1’, true, asserted, or high state. The lower voltage is called the ‘0’, false, not asserted, or low state. Figure 1.2.1 shows the output of a typical complementary metal oxide semiconductor (CMOS) circuit. The left side shows the condition with a true bit at the output, and the right side shows a false at the output. The output of each digital circuit consists of a p-type MOS transistor “on top of” an n-type MOS transistor. In digital circuits, each transistor is either on or off. If the transistor is on, it is equivalent to a short circuit between its two output pins. Conversely, if the transistor is off, it is equivalent to an open circuit between its outputs pins. A P-channel MOS transistor will be on (connecting two output pins) if its input is low. An N-channel MOS transistor will be on (connecting two output pins) if its input is high.
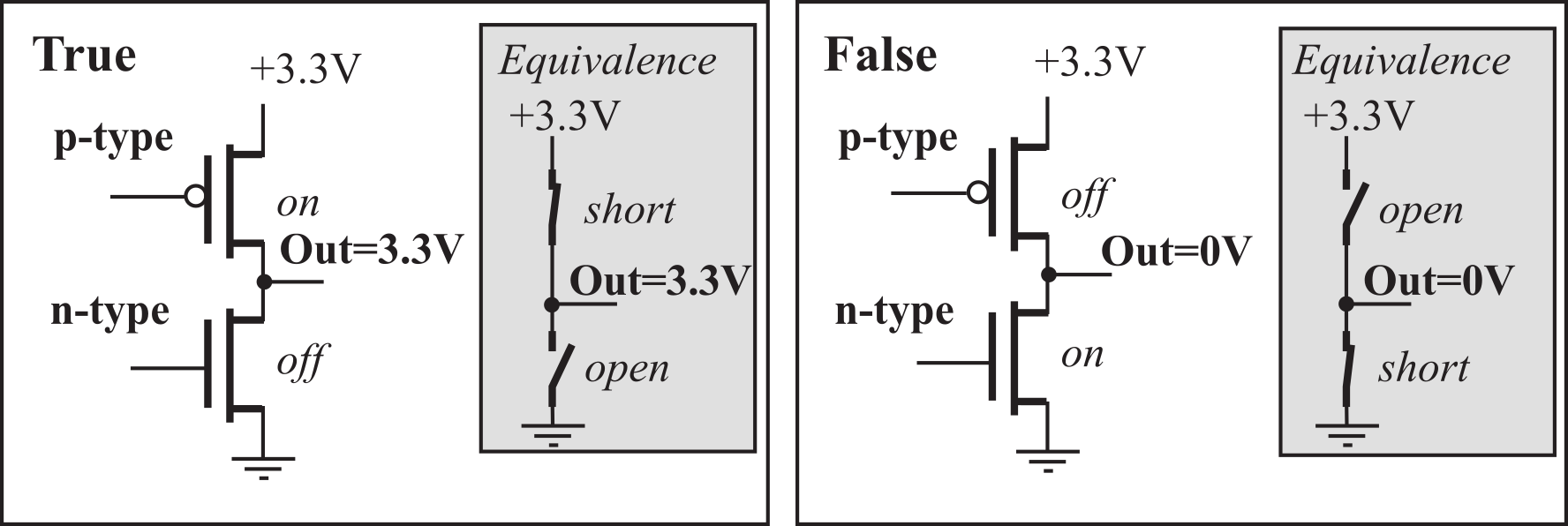
Figure 1.2.1. A binary bit at the output is true if a voltage is present and false if the voltage is 0.
: What would have if both transistors were on in Figure 1.2.1?
: What would have if both transistors were off in Figure 1.2.1?
Every family of digital logic is different, but on the MSPM0+ microcontrollers from TI powered with 3.3 V supply, an input voltage between 2.31 and 3.6 V is considered high, and an input voltage between 0 and 0.99 V is considered low. In general we define VIH as smallest input voltage considered high. A voltage between 0 and 0.99 V is considered low, as drawn in Figure 1.2.2. In general we define VIL as largest input voltage considered high. Separating the two regions by 1.32 V allows digital logic to operate reliably at very high speeds. The design of transistor-level digital circuits is beyond the scope of this book. However, it is important to know that digital data exist as binary bits and encoded as high and low voltages.
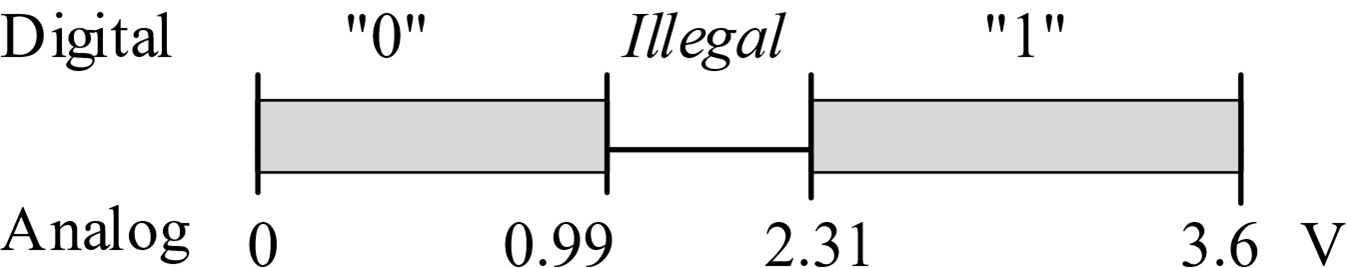
Figure 1.2.2. Mapping between the input voltage and the corresponding digital meaning on an MSPM0 input pin.
If the information we wish to store exists in more than two states, we use multiple bits. A collection of 2 bits has 4 possible states (00, 01, 10, and 11). A collection of 3 bits has 8 possible states (000, 001, 010, 011, 100, 101, 110, and 111). In general, a collection of n bits has 2n states. For example, a byte contains eight bits and is built by grouping eight binary bits into one object, as shown in Figure 1.2.3. Another name for a collection of eight bits is octet (octo is Latin and Greek meaning 8.) Information can take many forms, e.g., numbers, logical states, text, instructions, sounds, or images. What the bits mean depends on how the information is organized and more importantly how it is used. This figure shows one byte in the state representing the binary number 01100111, which could mean 103. As a character, this same collection of bits represents the letter ‘g’. Again, the output voltage 3.3V means true or 1, and the output voltage of 0V means false or 0.
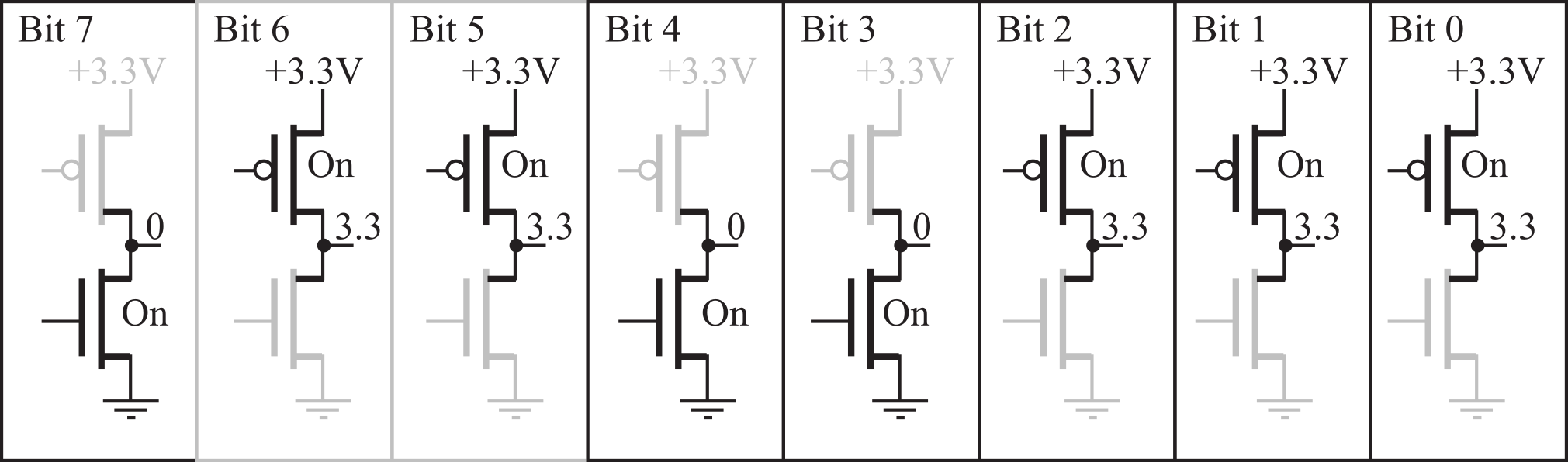
Figure 1.2.3. A byte is comprised of 8 bits, in this case representing the binary number 01100111.
: Why is there a gap between VIL and VIH?
: Our microcontroller is powered at 3.3V. Can you think of a reason to reduce the supply voltage to 1.65V?
Quiz 1.2
1.3. Numbers
A great deal of confusion exists over the abbreviations we use for large numbers. In 1998 the International Electrotechnical Commission (IEC) defined a new set of abbreviations for the powers of 2, as shown in Table 1.3.1. These new terms are endorsed by the Institute of Electrical and Electronics Engineers (IEEE) and International Committee for Weights and Measures (CIPM) in situations where the use of a binary prefix is appropriate. The confusion arises over the fact that the mainstream computer industry, such as Microsoft, Apple, and Dell, continues to use the old terminology. According to the companies that market to consumers, a 1 GHz is 1,000,000,000 Hz but 1 Gbyte of memory is 1,073,741,824 bytes. The correct terminology is to use the SI-decimal abbreviations to represent powers of 10, and the IEC-binary abbreviations to represent powers of 2. The scientific meaning of 2 kilovolts is 2000 volts, but 2 kibibytes is the proper way to specify 2048 bytes. The term kibibyte is a contraction of kilo binary byte and is a unit of information or computer storage, abbreviated KiB.
1 KiB = 210 bytes = 1024 bytes
1 MiB = 220 bytes = 1,048,576 bytes
1 GiB = 230 bytes = 1,073,741,824 bytes
These abbreviations can also be used to specify the number of binary bits. The term kibibit is a contraction of kilo binary bit, and is a unit of information or computer storage, abbreviated Kibit.
A mebibyte (1 MiB is 1,048,576 bytes) is approximately equal to a megabyte (1 MB is 1,000,000 bytes), but mistaking the two has nonetheless led to confusion and even legal disputes. In the engineering community, it is appropriate to use terms that have a clear and unambiguous meaning.
|
Value |
SI Decimal |
SI Decimal |
|
Value |
IEC Binary |
IEC Binary |
|
10001 |
k |
kilo- |
|
10241 |
Ki |
kibi- |
|
10002 |
M |
mega- |
|
10242 |
Mi |
mebi- |
|
10003 |
G |
giga- |
|
10243 |
Gi |
gibi- |
|
10004 |
T |
tera- |
|
10244 |
Ti |
tebi- |
|
10005 |
P |
peta- |
|
10245 |
Pi |
pebi- |
|
10006 |
E |
exa- |
|
10246 |
Ei |
exbi- |
|
10007 |
Z |
zetta- |
|
10247 |
Zi |
zebi- |
|
10008 |
Y |
yotta- |
|
10248 |
Yi |
yobi- |
Table 1.3.1. Common abbreviations for large numbers.
To solve problems using a computer we need to understand numbers and what they mean. Each digit in a decimal number has a place and a value. The place is a power of 10 and the value is selected from the set {0, 1, 2, 3, 4, 5, 6, 7, 8, 9}. A decimal number is simply a combination of its digits multiplied by powers of 10. For example
1984 = 1•103 + 9•102 + 8•101 + 4•100
Fractional values can be represented by using the negative powers of 10. For example,
273.15 = 2•102 + 7•101 + 3•100 + 1•10-1 + 5•10-2
In a similar manner, each digit in a binary number has a place and a value. In binary numbers, the place is a power of 2, and the value is selected from the set {0, 1}. A binary number is simply a combination of its digits multiplied by powers of 2. To eliminate confusion between decimal numbers and binary numbers, we will put a subscript 2 after the number to mean binary. Because of the way the microcontroller operates, most of the binary numbers in this class will have 8, 16, or 32 bits. An 8-bit number is called a byte, and a 16-bit number is called a halfword. For example, the 8-bit binary number for 106 is
011010102 = 0•27 + 1•26 + 1•25 + 0•24 + 1•23 + 0•22 + 1•21 + 0•20 = 64+32+8+2 = 106
: What is the numerical value of the 8-bit binary number 111111112?
Video 1.3.1. Binary representation
You have already learned how to convert from a binary number to its decimal representation. All you need to do is to calculate its value by multiplying each coefficient by its placeholder values and summing all of them together. If you want to practice, first think of an 8-digit binary number, and next type into the box from 1 to 8 binary digits. Try to calculate the decimal representation in your head. Then click "convert" to check your result.
Binary is the natural language of computers but a big nuisance for us humans. To simplify working with binary numbers, humans use a related number system called hexadecimal, which uses base 16. Just like decimal and binary, each hexadecimal digit has a place and a value. In this case, the place is a power of 16 and the value is selected from the set {0, 1, 2, 3, 4, 5, 6, 7, 8, 9, A, B, C, D, E, F}. As you can see, hexadecimal numbers have more possibilities for their digits than are available in the decimal format; so, we add the letters A through F, as shown in Table 1.3.2. Hexadecimal representation is a convenient mechanism for us humans to define binary information, because it is extremely simple for humans to convert back and forth between binary and hexadecimal.
Video 1.3.2. Hexadecimal representation
|
Hex Digit |
Decimal Value |
Binary Value |
|
0 |
0 |
0000 |
|
1 |
1 |
0001 |
|
2 |
2 |
0010 |
|
3 |
3 |
0011 |
|
4 |
4 |
0100 |
|
5 |
5 |
0101 |
|
6 |
6 |
0110 |
|
7 |
7 |
0111 |
|
8 |
8 |
1000 |
|
9 |
9 |
1001 |
|
A or a |
10 |
1010 |
|
B or b |
11 |
1011 |
|
C or c |
12 |
1100 |
|
D or d |
13 |
1101 |
|
E or e |
14 |
1110 |
|
F or f |
15 |
1111 |
Table 1.3.2. Definition of hexadecimal representation.
For example, the hexadecimal number for the 16-bit binary 0001 0010 1010 1101 is
0x12AD = 1•163 + 2•162 + 10•161 + 13•160 = 4096+512+160+13 = 4781
You have already learned how to convert from a hexadecimal number to its decimal representation. All you need to do is to calculate its value by multiplying each coefficient by its placeholder values and summing all of them together. If you want to practice, Choose an 4-digit hexadecimal number number. Try to calculate the decimal representation. Then type the number in the following field and click "convert" to check your result.
: What is the numerical value of the 8-bit hexadecimal number 0xFF?
: Convert the binary number 010001012 to hexadecimal.
: Convert the binary number 1100101010112 to hexadecimal.
: Convert the hex number 0x40 to binary.
: Convert the hex number 0x63F to binary.
: How many binary bits does it take to represent 0x123456?
Precision is the number of distinct or different values. We express precision in alternatives, decimal digits, bytes, or binary bits. Alternatives are defined as the total number of possibilities. For example, an 8-bit number format can represent 256 different numbers. An 8-bit digital to analog converter (DAC) can generate 256 different analog outputs. An 8-bit analog to digital converter (ADC) can measure 256 different analog inputs. Table 1.3.3 illustrates the relationship between precision in binary bits and precision in alternatives. The operation [[x]] is defined as the greatest integer of x. E.g., [[2.1]] [[2.9]] and [[3.0]] are all equal to 3. The Bytes column in Table 2.1 specifies how many bytes of memory it would take to store a number with that precision assuming the data were not packed or compressed in any way.
|
Binary bits |
Bytes |
Alternatives |
|
8 |
1 |
256 |
|
10 |
2 |
1024 |
|
12 |
2 |
4096 |
|
16 |
2 |
65536 |
|
20 |
3 |
1,048,576 |
|
24 |
3 |
16,777,216 |
|
30 |
4 |
1,073,741,824 |
|
32 |
4 |
4,294,967,296 |
|
n |
[[n/8]] |
2n |
Table 1.3.3. Relationship between bits, bytes and alternatives as units of precision.
: How many bytes of memory would it take to store a 50-bit number?
A byte contains 8 bits as shown in Figure 1.3.1, where each bit b7,...,b0 is binary and has the value 1 or 0. We specify b7 as the most significant bit or MSB, and b0 as the least significant bit or LSB.

Figure 1.3.1. 8-bit binary format.
If a byte is used to represent an unsigned number, then the value of the number is
N = 128•b7 + 64•b6 + 32•b5 + 16•b4 + 8•b3 + 4•b2 + 2•b1 + b0
Notice that the significance of bit n is 2n. There are 256 different unsigned 8-bit numbers. The smallest unsigned 8-bit number is 0 and the largest is 255. For example, 000010102 is 8+2 or 10. The least significant bit can tell us if the number is even or odd.
: Convert the binary number 011010012 to unsigned decimal.
: Convert the hex number 0x54 to unsigned decimal.
The basis of a number system is a subset from which linear combinations of the basis elements can be used to construct the entire set. The basis represents the “places” in a “place-value” system. For positive integers, the basis is the infinite set {1, 10, 100, …}, and the “values” can range from 0 to 9. Each positive integer has a unique set of values such that the dot-product of the value vector times the basis vector yields that number. For example, 2345 is (…, 2,3,4,5)·(…, 1000,100,10,1), which is 2*1000+3*100+4*10+5. For the unsigned 8-bit number system, the basis elements are
{1, 2, 4, 8, 16, 32, 64, 128}
The values of a binary number system can only be 0 or 1. Even so, each 8-bit unsigned integer has a unique set of values such that the dot-product of the values times the basis yields that number. For example, 69 is (0,1,0,0,0,1,0,1)·(128,64,32,16,8,4,2,1), which equals 0*128+1*64+0*32+0*16+0*8+1*4+0*2+1*1. Conveniently, there is no other set of 0’s and 1’s, such that set of values multiplied by the basis is 69. In other words, each 8-bit unsigned binary representation of the values 0 to 255 is unique.
One way for us to convert a decimal number into binary is to use the basis elements. The overall approach is to start with the largest basis element and work towards the smallest. More precisely, we start with the most significant bit and work towards the least significant bit. One by one, we ask ourselves whether or not we need that basis element to create our number. If we do, then we set the corresponding bit in our binary result and subtract the basis element from our number. If we do not need it, then we clear the corresponding bit in our binary result. We will work through the algorithm with the example of converting 100 to 8-bit binary, see Table 2.4. We start with the largest basis element (in this case 128) and ask whether or not we need to include it to make 100? Since our number is less than 128, we do not need it, so bit 7 is zero. We go the next largest basis element, 64 and ask, “do we need it?” We do need 64 to generate our 100, so bit 6 is one and we subtract 100 minus 64 to get 36. Next, we go the next basis element, 32 and ask, “do we need it?” Again, we do need 32 to generate our 36, so bit 5 is one and we subtract 36 minus 32 to get 4. Continuing along, we do not need basis elements 16 or 8, but we do need basis element 4. Once we subtract the 4, our working result is zero, so basis elements 2 and 1 are not needed. Putting it together, we get 011001002 (which means 64+32+4).
: In this conversion algorithm, how can we tell if a basis element is needed?
Observation: If the least significant binary bit is zero, then the number is even.
Observation: If the right-most n bits (least sign.) are zero, then the number is divisible by 2n.
Observation: Consider an 8-bit unsigned number system. If bit 7 is low, then the number is between 0 and 127, and if bit 7 is high then the number is between 128 and 255.
: Give the representations of the decimal 45 in 8-bit binary and hexadecimal.
: Give the representations of the decimal 200 in 8-bit binary and hexadecimal.
There are a few techniques for converting decimal numbers to binaries. One of them is consecutive divisions. We start by dividing the decimal number by 2. Then we iteratively divide the result (the quotient) by 2 until the answer is 0. The equivalent binary is formed by the remainders of the divisions. The last remainder found is the most significant digit. Enter a number between 0 and 255 in the following field and click convert to see an example. Try to convert a decimal number to binary.
|
|
|
One of the first schemes to represent signed numbers was called one’s complement. It was called one’s complement because to negate a number, we complement (logical not) each bit. For example, if 25 equals 000110012 in binary, then –25 is 111001102. An 8-bit one’s complement number can vary from ‑127 to +127. The most significant bit is a sign bit, which is 1 if and only if the number is negative. The difficulty with this format is that there are two zeros +0 is 000000002, and –0 is 111111112. Another problem is that one’s complement numbers do not have basis elements. These limitations led to the use of two’s complement.
The two’s complement number system is the most common approach used to define signed numbers. It is called two’s complement because to negate a number, we complement each bit (like one’s complement), then add 1. For example, if 25 equals 000110012 in binary, then –25 is 111001112. If a byte is used to represent a signed two’s complement number, then the value of the number is
N = -128•b7 + 64•b6 + 32•b5 + 16•b4 + 8•b3 + 4•b2 + 2•b1 + b0
Observation: One usually means two’s complement when one refers to signed integers.
There are 256 different signed 8-bit numbers. The smallest signed 8-bit number is -128 and the largest is 127. For example, 100000102 equals -128+2 or -126.
: Convert the signed binary number 110110102 to signed decimal.
: Are the signed and unsigned decimal representations of the 8-bit hex number 0x95 the same or different?
For the signed 8-bit number system the basis elements are
{1, 2, 4, 8, 16, 32, 64, -128}
Observation: The most significant bit in a two’s complement signed number will specify the sign.
Notice that the same binary pattern of 111111112 could represent either 255 or –1. It is very important for the software developer to keep track of the number format. The computer cannot determine whether the 8‑bit number is signed or unsigned. You, as the programmer, will determine whether the number is signed or unsigned by the specific assembly instructions you select to operate on the number. Some operations like addition, subtraction, and shift left (multiply by 2) use the same hardware (instructions) for both unsigned and signed operations. On the other hand, divide, and shift right (divide by 2) require separate hardware (instruction) for unsigned and signed operations.
Observation: To take the negative of a two’s complement signed number we first complement (flip) all the bits, then add 1.
A second way to convert negative numbers into binary is to first convert them into unsigned binary, then do a two’s complement negate. For example, we earlier found that +100 is 011001002. The two’s complement negate is a two-step process. First we do a logic complement (flip all bits) to get 100110112. Then add one to the result to get 100111002.
: Give the representations of -54 in 8-bit binary and hexadecimal.
: Why can’t you represent the number 150 using 8-bit signed binary?
When dealing with numbers on the computer, it will be convenient to memorize some Powers of 2 as shown in Table 1.3.4.
|
exponent |
decimal |
|
20 |
1 |
|
21 |
2 |
|
22 |
4 |
|
23 |
8 |
|
24 |
16 |
|
25 |
32 |
|
26 |
64 |
|
27 |
128 |
|
28 |
256 |
|
29 |
512 |
|
210 |
1024 about a thousand |
|
211 |
2048 |
|
212 |
4096 |
|
213 |
8192 |
|
214 |
16384 |
|
215 |
32768 |
|
216 |
65536 |
|
220 |
about a million |
|
230 |
about a billion |
|
240 |
about a trillion |
Table 1.3.4. Some powers of two that will be useful to memorize.
: Use Table 1.3.4 to determine the approximate value of 232?
A halfword or double byte contains 16 bits, where each bit b15,...,b0 is binary and has the value 1 or 0, as shown in Figure 1.3.2.
![]()
Figure 1.3.2. 16-bit binary format.
If a halfword is used to represent an unsigned number, then the value of the number is
N = 32768•b15 + 16384•b14 + 8192•b13 + 4096•b12
+ 2048•b11 + 1024•b10 + 512•b9 + 256•b8
+ 128•b7 + 64•b6 + 32•b5 + 16•b4 + 8•b3 + 4•b2 + 2•b1 + b0
There are 65536 different unsigned 16-bit numbers. The smallest unsigned 16-bit number is 0 and the largest is 65535. For example, 00100001100001002 or 0x2184 is 8192+256+128+4 or 8580.
: Convert the 16-bit binary number 00100000011010102 to unsigned decimal.
: Convert the 16-bit hex number 0x1234 to unsigned decimal.
For the unsigned 16-bit number system the basis elements are
{1, 2, 4, 8, 16, 32, 64, 128, 256, 512, 1024, 2048, 4096, 8192, 16384, 32768}
: Convert the unsigned decimal number 1234 to 16-bit hexadecimal.
: Convert the unsigned decimal number 10000 to 16-bit binary.
There are also 65536 different signed 16-bit numbers. The smallest two’s complement signed 16‑bit number is –32768 and the largest is 32767. For example, 11010000000001002 or 0xD004 is –32768+16384+4096+4 or –12284.
If a halfword is used to represent a signed two’s complement number, then the value of the number is
N = -32768•b15 + 16384•b14 + 8192•b13 + 4096•b12
+ 2048•b11 + 1024•b10 + 512•b9 + 256•b8
+ 128•b7 + 64•b6 + 32•b5 + 16•b4 + 8•b3 + 4•b2 + 2•b1 + b0
: Convert the 16-bit hex number 0x1234 to signed decimal.
: Convert the 16-bit hex number 0xABCD to signed decimal.
For the signed 16-bit number system the basis elements are
{1, 2, 4, 8, 16, 32, 64, 128, 256, 512, 1024, 2048, 4096, 8192, 16384, -32768}
Common Error: An error will occur if you use 16-bit operations on 8-bit numbers, or use 8-bit operations on 16-bit numbers.
Maintenance Tip: To improve the clarity of your software, always specify the precision of your data when defining or accessing the data.
: Convert the signed decimal number 1234 to 16-bit hexadecimal.
: Convert the signed decimal number –10000 to 16-bit binary.
A word on the ARM Cortex M will have 32 bits. Consider an unsigned number with 32 bits, where each bit b31,...,b0 is binary and has the value 1 or 0. If a 32-bit number is used to represent an unsigned integer, then the value of the number is
N = 231 • b31 + 230 • b30 + ... + 2•b1 + b0 = sum(2i • bi) for i=0 to 31
There are 232 different unsigned 32-bit numbers. The smallest unsigned 32-bit number is 0 and the largest is 232-1 (4,294,967,295). This range is 0 to about 4 billion. For the unsigned 32-bit number system, the basis elements are
{1, 2, 4, ... , 229, 230, 231}
If a 32-bit binary number is used to represent a signed two’s complement number, then the value of the number is
N = -231 • b31 + 230 • b30 + ... + 2•b1 + b0 = -231 • b31 + sum(2i • bi) for i=0 to 30
There are also 232 different signed 32-bit numbers. The smallest signed 32-bit number is -231 (-2,147,483,648) and the largest is 231-1 (+2,147,483,647). This range is about -2 billion to about +2 billion. For the signed 32-bit number system, the basis elements are
{1, 2, 4, ... , 229, 230, -231}
The computer does not distinguish between signed and unsigned numbers in memory. The interpretation is yours to make. Enter an 8-bit binary number in the following field and press "show" to see its value if interpreted as signed or unsigned integer. For convenience, you can also enter hexadecimal input with '0x' prefix.
Video 1.3.3. Signed versus unsigned numbers
Quiz 1.3
1.4. Introduction to Computers
Video 1.4.1. Computer Organization
A computer combines a processor, random access memory (RAM), read only memory (ROM), and input/output (I/O) ports. Computers are not intelligent. Rather, you are the true genius. Computers are electronic idiots. They can store a lot of data, but they will only do exactly what we tell them to do. Fortunately, however, they can execute our programs quite quickly, and they don’t get bored doing the same tasks over and over again. Software is an ordered sequence of very specific instructions that are stored in memory, defining exactly what and when certain tasks are to be performed. It is a set of instructions, stored in memory, that are executed in a complicated but well-defined manner. The processor executes the software by retrieving and interpreting these instructions one at a time. A microprocessor is a small processor, where small refers to size (i.e., it fits in your hand) and not computational ability.
A microcomputer is a small computer, where again small refers to size (i.e., you can carry it) and not computational ability. For example, a desktop PC is a microcomputer. Small in this context describes its size not its computing power. Consequently, there can be great confusion over the term microcomputer, because it can refer to a very wide range of devices from a PIC12C508, which is an 8-pin chip with 512 words of ROM and 25 bytes RAM, to the most powerful I7-based personal computer.
A pin is a signal or wire on the microcomputer. Figure 1.4.1 shows MSPM0G3507 has 64 pins. A port is a collection of pins, providing a physical connection between the computer and its outside world. Ports allow information to enter and exit the system. Information enters via the input ports and exits via the output ports. Other names used to describe ports are I/O ports, I/O devices, interfaces, or sometimes just devices. A bus is a collection of wires used to pass information between modules.
A very small microcomputer, called a microcontroller, contains all the components of a computer (processor, memory, I/O) on a single chip. As shown in Figure 1.4.1, the Atmel ATtiny, the Texas Instruments MSP430, and the Texas Instruments MSPM0G3507 are examples of microcontrollers. Because a microcomputer is a small computer, this term can be confusing because it is used to describe a wide range of systems from a 6-pin ATtiny4 running at 1 MHz with 512 bytes of program memory to a personal computer with state-of-the-art 64-bit multi-core processor running at multi-GHz speeds having terabytes of storage.
The computer can store information in RAM by writing to it, or it can retrieve previously stored data by reading from it. RAMs are volatile; meaning if power is interrupted and restored the information in the RAM is lost.

Figure 1.4.1. A microcontroller is a complete computer on a single chip.
Information is programmed into ROM using techniques more complicated than writing to RAM. From a programming viewpoint, retrieving data from a ROM is identical to retrieving data from RAM. ROMs are nonvolatile; meaning if power is interrupted and restored the information in the ROM is retained.
Figure 1.4.2 shows a simplified block diagram of a microcontroller based on the ARM® Cortex™-M4 processor. It is a Harvard architecture because it has separate data and instruction buses. Instructions are fetched from flash ROM using the ICode bus at the same time as Data are exchanged with memory and I/O via the System bus interface.
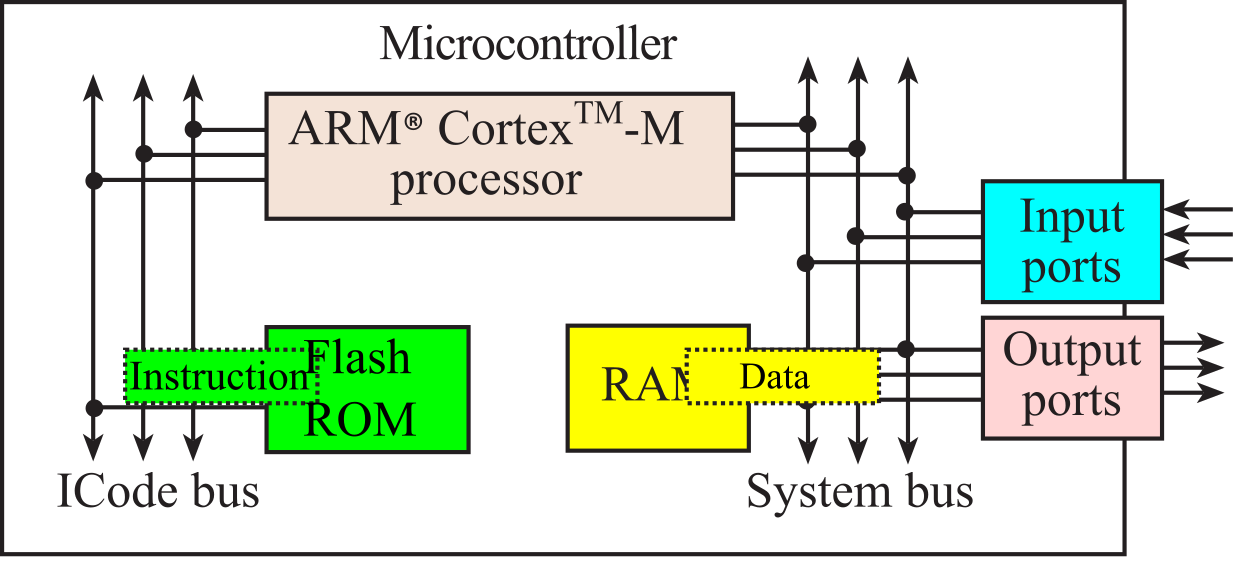
Figure 1.4.2. Harvard architecture of an ARM® Cortex-M4-based microcontroller. Notice multiple buses allow simultaneous data flow.
The common bus in Figure 1.4.3 defines the von Neumann architecture, because a single bus is used for both data and instructions.
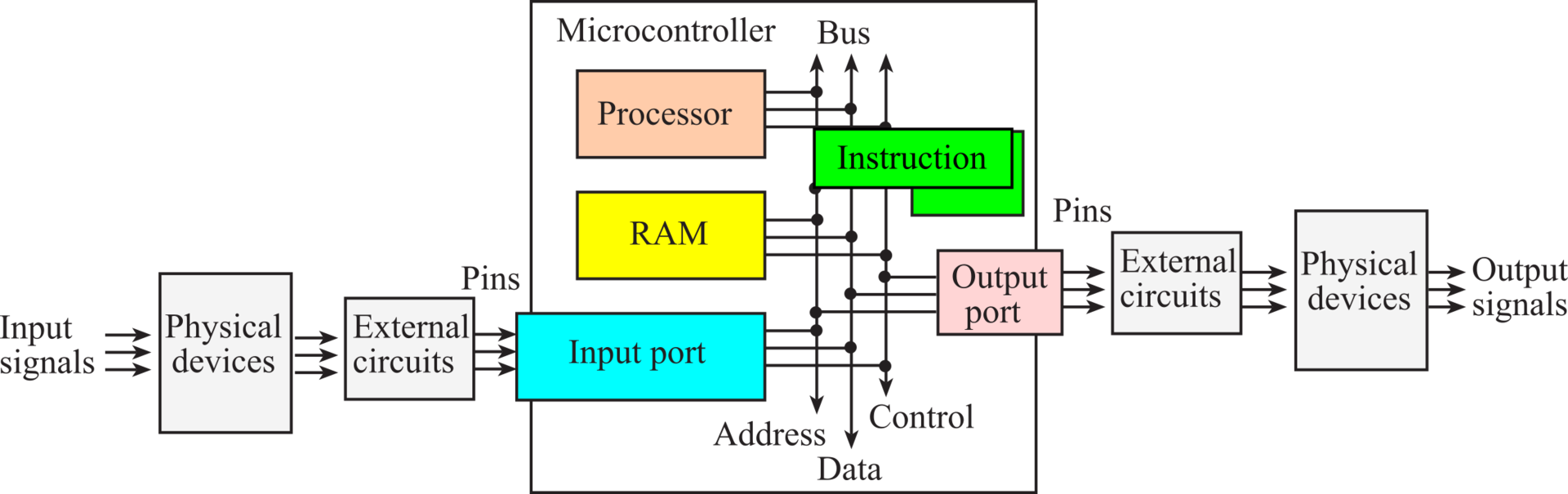
Figure 1.4.3. von Neumann architecture of an ARM® Cortex-M0-based microcontroller. Notice the single bus requires data to flow one at a time.
: What are the differences between a microcomputer, a microprocessor, and a microcontroller?
: What are three differences between RAM and ROM?
: What is the difference between Harvard and von Neumann architectures?
Quiz 1.4
1.5. Memory
Figure 1.5.1 shows the memory map of the MSPM0G3507. A 32-bit entry requires four sequential locations. The I/O ports exist as memory-mapped locations. I/O ports are not memory, but we will write to an I/O port address to output and read from an I/O port address to input.
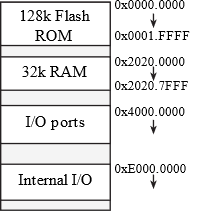
Figure 1.5.1. Memory map. Each address contains 8 bits or 1 byte.
Video 1.5.1. Memory Map Layout***needs recording***
When we store 16-bit data into memory it requires two bytes. Since the memory systems on most computers are byte addressable (a unique address for each byte), there are two possible ways to store in memory the two bytes that constitute the 16-bit data. Many main-frame computers, like the z/Architecture, implement the big endian approach that stores the most significant byte at the lower address. Most smaller computers (desktops, laptops, phones and microcontrollers) implement the little endian approach that stores the least significant byte at the lower address. The Cortex-M microcontrollers use the little endian format. Many ARM processors are biendian, because they can be configured to efficiently handle both big and little endian data. Instruction fetches on the ARM are always little endian. Figure 1.5.2 shows two ways to store the 16-bit number 1000 (0x03E8) at locations 0x20200850 and 0x20200851. We also could use either the big or little endian approach when storing 32-bit numbers into memory that is byte (8-bit) addressable. Figure 1.5.3 shows the big and little endian formats that could be used to store the 32-bit number 0x12345678 at locations 0x20200850 through 0x20200853.
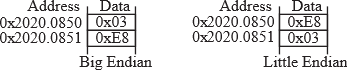
Figure 1.5.2. Example of big and little endian formats of a 16-bit number (the Cortex M used little endian).

Figure 1.5.3. Example of big and little endian formats of a 32-bit number (the Cortex M used little endian).
In the previous two examples, we normally would not pick out individual bytes (e.g., the 0x12), but rather capture the entire multiple byte data as one nondivisable piece of information. On the other hand, if each byte in a multiple byte data structure is individually addressable, then both the big and little endian schemes store the data in first to last sequence. For example, if we wish to store the four ASCII characters ‘LM3S’, which is 0x4C4D3353 at locations 0x20200850 through 0x20200853, then the ASCII ‘L’=0x4C comes first in both big and little endian schemes, as illustrated in Figure 1.5.4.

Figure 1.5.4. Character strings are stored in the same for both big and little endian formats.
The terms “big and little endian” come from Jonathan Swift’s satire Gulliver’s Travels. In Swift’s book, a Big Endian refers to a person who cracks their egg on the big end. The Lilliputians were Little Endians because they insisted that the only proper way is to break an egg on the little end. The Lilliputians considered the Big Endians as inferiors. The Big and Little Endians fought a long and senseless war over the best way to crack an egg.
Common Error: An error will occur when data is stored in Big Endian by one computer and read in Little Endian format on another.
: Consider memory shown in Figure 1.5.4. What would you get if you did an 8-bit read from location 0x2020.0850?
: Consider memory shown in Figure 1.5.4. What would you get if you did a 16-bit read from location 0x2020.0850?
: Consider memory shown in Figure 1.5.4. What would you get if you did a 32-bit read from location 0x2020.0850?
Quiz 1.5
1.6. Pseudo-ops
A pseudo-op is an assembler directive to affect the assembly process. We use the .data pseudo-op to specify what information goes in RAM and the .text pseudo-op to specify what information what goes in ROM. We will use a template similar to Program 1.6.1 for most assembly programs in this class. The .equ pseudo-ops create symbols containing the address of some the I/O port registers. The .data pseudo-op means the subsequent code will be placed in volatile RAM. The .align 2 pseudo-op skips 0-3 bytes so the address of next object is word aligned (bottom two bits of the address are 0). The .space pseudo-op allocates 4 bytes (in RAM) for the variable named Stuff. The .text pseudo-op means the subsequent code will be placed in nonvolatile ROM. The .thumb pseudo-op tells the assembler to create Thumb code. The .global pseudo-op allows the label main to be accessed from another file. In particular, main will be the place the software starts on power up or on reset. The B Loop instruction creates an infinite loop, typical of embedded systems, causing the code between Loop and B Loop to be executed over and over.
.equ GPIOA_DOE31_0, 0x400A12C0
.equ GPIOA_DOUT31_0, 0x400A1280
.equ GPIOA_DIN31_0, 0x400A1380
.data
.align 2
// Global variables defined here, will go in RAM
Stuff: .space 4
.text
.align 2
.thumb
.global main
main:
//assembly code to be executed once and first goes here
Loop:
// assembly code to be executed over and over goes here
B Loop
.end // end of file
Program 1.6.1. Template for assembly language programs.
: What is the purpose of the 4 in the Stuff: .space 4 pseudo-op?
: What is the purpose of the .data pseudo-op?
: What is the purpose of the .text pseudo-op?
Here is a partial list of pseudo-ops used to declare memory and literals that we use in this e-book:
|
Pseudo-op |
Syntax |
Examples |
Description |
|
.byte |
name: .byte {,…} |
Score: .byte 95 |
Declare 8-bit value(s) in RAM or ROM, in
the range 0x00-0xFF |
|
.short, .hword |
name: .short {,…} |
Sum: .short -1025 FilterPairs: .short 1096, 2025, 1905, 4245,-1 |
Declare a 16-bit value in RAM or ROM, in
the range 0x0000-0x00FF |
|
.long, .word |
name:.long {,…} |
value: .long 0x1E240 Xvalues: .long 234567, -123456, -65, 125, 0 |
Declare a 32-bit value in RAM or ROM, in
the range 0x00000000-0xFFFFFFFF |
| .string, .ascii | name: .string "…" | Flavor: .string "cherry lime" | Declare a null-terminated ascii character string in RAM or ROM, |
|
.space |
name: .space size |
Result: .space 2 ResultsArray: .space 80 |
Declare an arbitrary amount of space
(bytes) in RAM |
|
.equ |
.equ name, expr |
.equ Addr, 0x2020000C .equ Magic, 42 |
Assign a literal to represent a
specific value (does not occupy space) |
|
.req |
name .req reg |
Count .req r1 Num .req r2 |
Assign a symbolic name to a register
(does not occupy space) |
Table 1.7. Psuedo-ops for declaring data.
Note that the .equ pseudo-op defines a symbolic name for a value. The assembler literally replaces every occurence of the name with the corresponding value, hence the term literal is used to describe what the .equ pseudo-op does. The .req pseudo-op does the same except it is restricted only to registers.
Quiz 1.6
1.7. Instruction Set Architecture
Video 1.7.1. Instruction set architecture.
Another term that is commonly used to describe a computer is by its Instruction Set Architecture (ISA), which is an abstract model of the computer that defines how the software views it. The MSPM0G3507 microcontroller with the ARM Cortex M0+ processor (aka CPU) implements the Armv6-M ISA. Broadly speaking, there are five parts to describing the ISA:
- Set of Instructions: Specifies the vocabulary or the set of commands that the software can issue to the computer. The Armv6-M ISA specifies 16-bit (Thumb) and some 32-bit (Thumb-2) instructions. These can be viewed as Data-Movement instructions, Arithmetic-Logic intructions and Control Instructions. Refer to the ISA Document for the complete set of instructions and the Appendix for a subset of the instructions that we use in this e-book.
- Registers: Specifies the set of General Purpose registers and Special registers available. The Armv6-M ISA specifies R0-R12 as general purpose registers and registers R13, R14 and R15 respectively are special registers SP (Stack Pointer), LR (Link Register) and PC (Program Counter). In addition, the Program Status Register (PSR), the Exception Mask Register (PRIMASK) and the Control Register (CONTROL) hold status flags and interrupt information, exception information and Stack related in information. The key status flags or condition-code bits supported are N, Z, V and C, which denote Negative, Zero, Signed Overflow and Unsigned Overflow result respectively.
- Memory Layout: Specifies the Address Space and Addressability of the memory and, what the various regions of memory map the ROM, the RAM and device registers. The Address Space of the Armv6-M ISA is 232 bytes, which represents the total addressable memory, which implies that the Memory Address Register and so the Address Bus is 32-bits wide. The Addressability is the unit of memory transfer (read/write), which is 8-bit, 16-bit or 32-bit for this ISA.
- Addressing Modes: Specifies the method for representing an operand in a given assembly instruction. The Armv6-M ISA supports, immediate, register, pc-relative and base+offset (aka indexed) addressing modes.
- Data-Types: Specifies the primitive data-types supported. The Armv6-M supports many data-types but we will restrict our use to the following: char, signed and unsigned integers at 8-bit, 16-bit or 32-bit size (see pseudo-ops for more details).
This section is a brief introduction to the ARM® Cortex™-M0+ instruction set architecture. There are many ARM® processors, and this class focuses on Cortex-M microcontrollers, which executes Thumb® instructions extended with Thumb-2 technology. This class will not describe in detail all the Thumb instructions. Rather, we focus on only a subset of the Thumb® instructions. This subset will be functionally complete without regard to minimizing code size or optimizing for execution speed. Furthermore, we will show the simple forms of instructions, but in many cases there are specific restrictions on which registers can be used and the sizes of the constants.
1.7.1. Registers
Registers are high-speed storage inside the processor. The registers are depicted in Figure 1.7.1. R0 to R7 are general purpose registers and contain either data or addresses. R8-R12 are virtually unusable because only the MOV and ADD instructions allow access to R8-R12. Register R13 (also called the stack pointer, SP) points to the top element of the stack. Register R14 (also called the link register, LR) is used to store the return location for functions. The LR is also used in a special way during exceptions, such as interrupts. Interrupts are covered in Chapter 5. Register R15 (also called the program counter, PC) points to the next instruction to be fetched from memory. The processor fetches an instruction using the PC and then increments the PC.
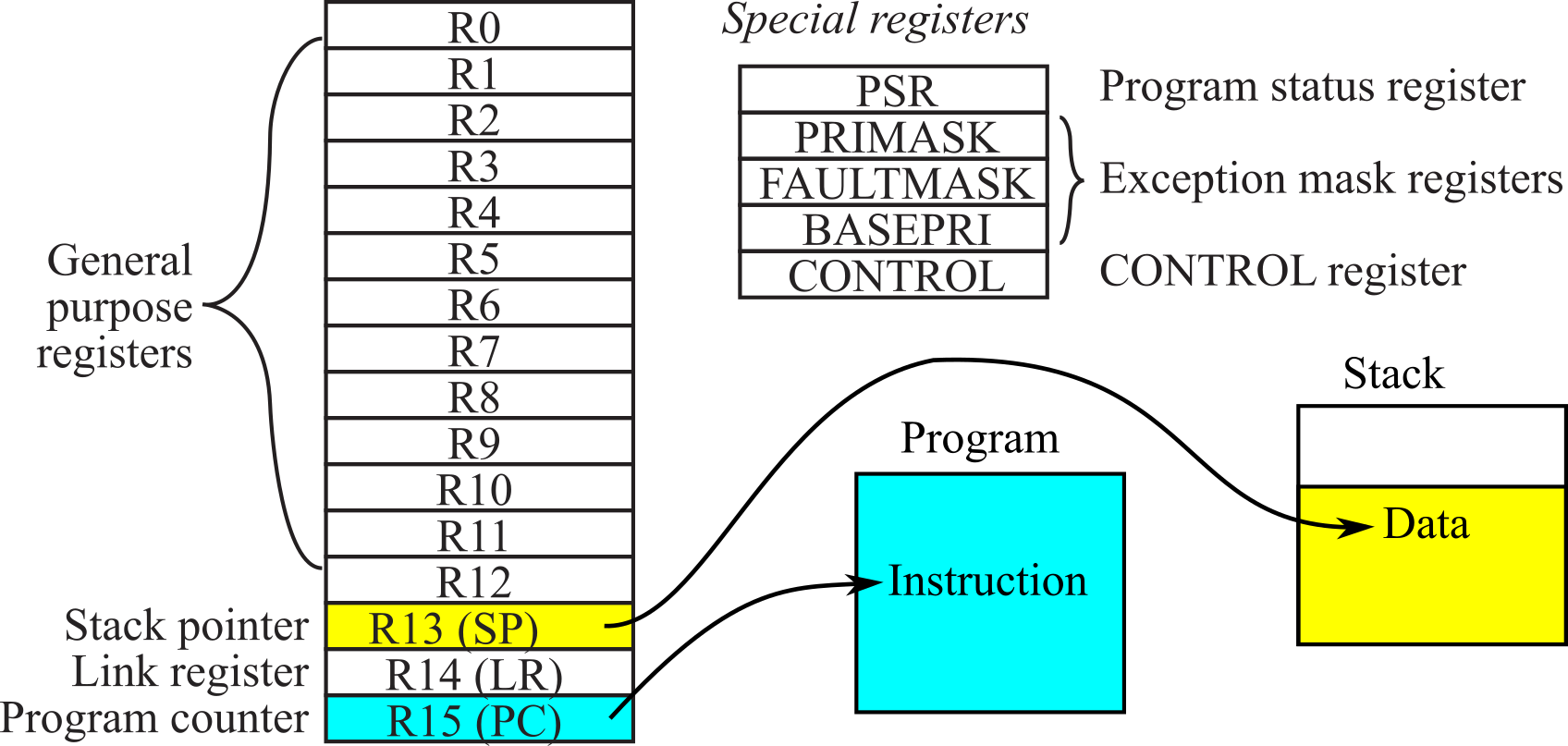
Figure 1.7.1. Registers on the ARM Cortex-M processor.
: Where in memory should you put the stack? I.e., does the SP point to RAM or ROM?
: Where in memory should you put the program? I.e., does the PC point to RAM or ROM?
The ARM Architecture Procedure Call Standard, AAPCS, part of the ARM Application Binary Interface (ABI), uses registers R0, R1, R2, and R3 to pass input parameters into a C function. Also according to AAPCS we place the return parameter in Register R0.
Video 1.7.2. Arm Architecture Procedure Call standard.
There are three status registers named Application Program Status Register (APSR), the Interrupt Program Status Register (IPSR), and the Execution Program Status Register (EPSR) as shown in Figure 1.7.2. These registers can be accessed individually or in combination as the Program Status Register (PSR). The N, Z, V, and C bits give information about the result of a previous ALU operation. In general, the N bit is set after an arithmetical or logical operation signifying whether or not the result is negative. Similarly, the Z bit is set if the result is zero. The C bit means carry and is set on an unsigned overflow, and the V bit signifies signed overflow.

Figure 1.7.2. The program status register of the ARM® Cortex-M processor.
The T bit will always be 1, indicating the ARM® Cortex™-M processor is executing Thumb® instructions. The ISR_NUMBER indicates which interrupt if any the processor is handling. Bit 0 of the special register PRIMASK is the interrupt mask bit. If this bit is 1, most interrupts and exceptions are not allowed. If the bit is 0, then interrupts are allowed. There are four levels of interrupt priority. The BASEPRI register defines the priority of the executing software. It prevents interrupts with lower or equal priority but allows higher priority interrupts. For example if BASEPRI equals 2, then requests with level 0 and 1 can interrupt, while requests at levels 2 or 3 will be postponed. A lower number means a higher priority interrupt. The details of interrupt processing will be presented in Chapter 5.
1.7.2. Syntax
Assembly language instructions have four fields separated by spaces or tabs. The label field is optional and starts in the first column and is used to identify the position in memory of the current instruction. You must choose a unique name for each label. The opcode field specifies the processor command to execute. The operand field specifies where to find the data to execute the instruction. Thumb instructions have 0, 1, 2, 3, or 4 operands, separated by commas. The comment field is also optional and is ignored by the assembler, but it allows you to describe the software making it easier to understand. You can add optional spaces between operands in the operand field. However, a // must separate the operand and comment fields. Good programmers add comments to explain the software.
Label Opcode Operands Comment
Func:
MOVS
R0,
#100
// 100 means maximum
BX
LR
Observation: A good comment explains why an operation is being performed, how it is used, how it can be changed, or how it was debugged. A bad comment explains what the operation does. The comments in the above two assembly lines are examples of bad comments.
The assembly source code is a text file (with Windows file extension .s) containing a list of instructions. The assembler translates assembly source code into object code, which are the machine instructions executed by the processor. All object code is halfword-aligned. This means instructions can be 16 or 32 bits wide, and the program counter bit 0 will always be 0. The listing is a text file containing a mixture of the object code generated by the assembler together with our original source code.
Label Opcode Operand comment
Func: MOVS R1,#0x64 // R1=100
MULS R0,R0,R1 // R0=100*input
ADDS R0,R0,#10 // R0=100*input+10
BX LR // return 100*input+10
When we build a project all files are assembled or compiled then linked together. The linker decides exactly where in memory everything will be. After building the project, it can be downloaded, which programs the object code into flash ROM. You are allowed to load and execute software out of RAM. But for an embedded system, we typically place executable instructions into nonvolatile ROM. The map file shows where in memory your variables and instructions exist.
1.7.3. Reading from and writing to memory
The first action we present is bringing a constant value into a register. With immediate addressing mode, the data itself is contained in the instruction. Once the instruction is fetched no additional memory access cycles are required to get the data. Notice the number 100 (0x64) is embedded in the machine code of the MOVS instruction shown in Figure 1.6.3.
MOVS R0,#100 // R0=100, immediate addressing
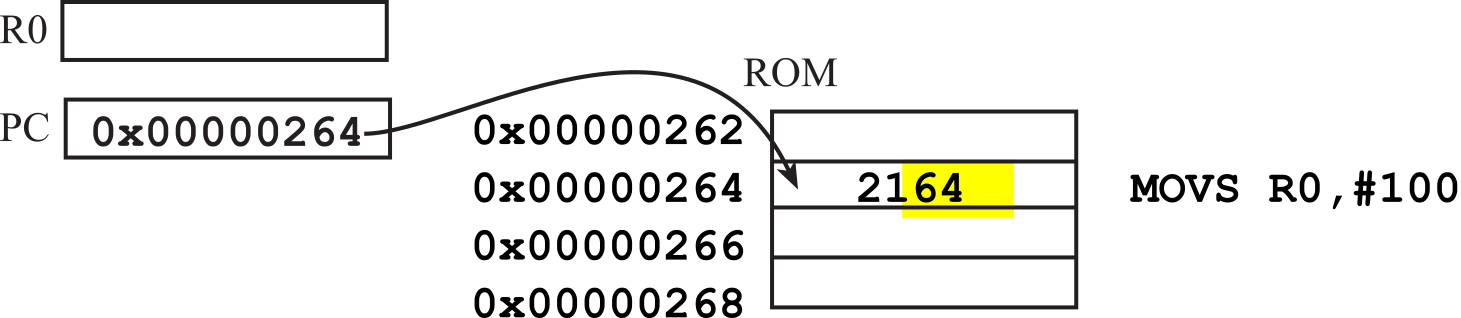
Figure 1.7.3. An example of immediate addressing mode, data is in the instruction.
The constant value allowed by MOVS is limited to 8-bit values. On the other hand, the LDR instruction can be used to bring any 32-bit value into a register. Notice the number 0x12345678 is not embedded in the machine code of the instruction, but rather stored in ROM a short distance away, as shown in Figure 1.7.4. The assembler automatically places the constant in ROM and calculates the appropriate PC-relative offset. At the time of execution, the PC is pointing to the next instruction.
LDR R0,=0x12345678 // R0=0x12345678, PC-relative addressing
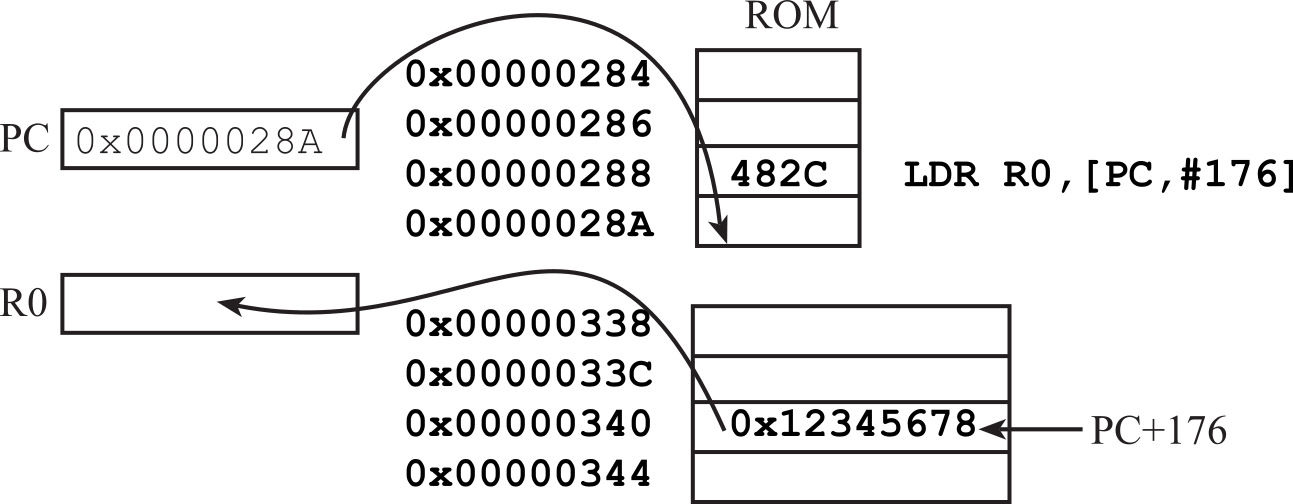
Figure 1.7.4. An example of using the LDR instruction to load any constant into a register.
Video 1.7.3. Assembly language access to RAM and ROM variables. ***needs recording***
A fundamental issue in program development is the
differentiation between data and address. When we put the number 100
into Register R0, whether this is data or address depends on how the 100
is used. As presented in Program 1.6.1, we created a 32-bit global
variable called Stuff. To write an initial value of 100 into
this variable will take three instructions. In this example, R0 has data
and R1 had an address. First, the MOVS instruction brings the
desired value into R0. Second, the LDR instruction sets R1 to
point to the global variable Stuff. Lastly, the STR instruction
writes the value into the variable.
MOVS R0,#100
LDR
R1,=Stuff // R1 points to the variable Stuff
STR
R0,[R1] // Stuff=100
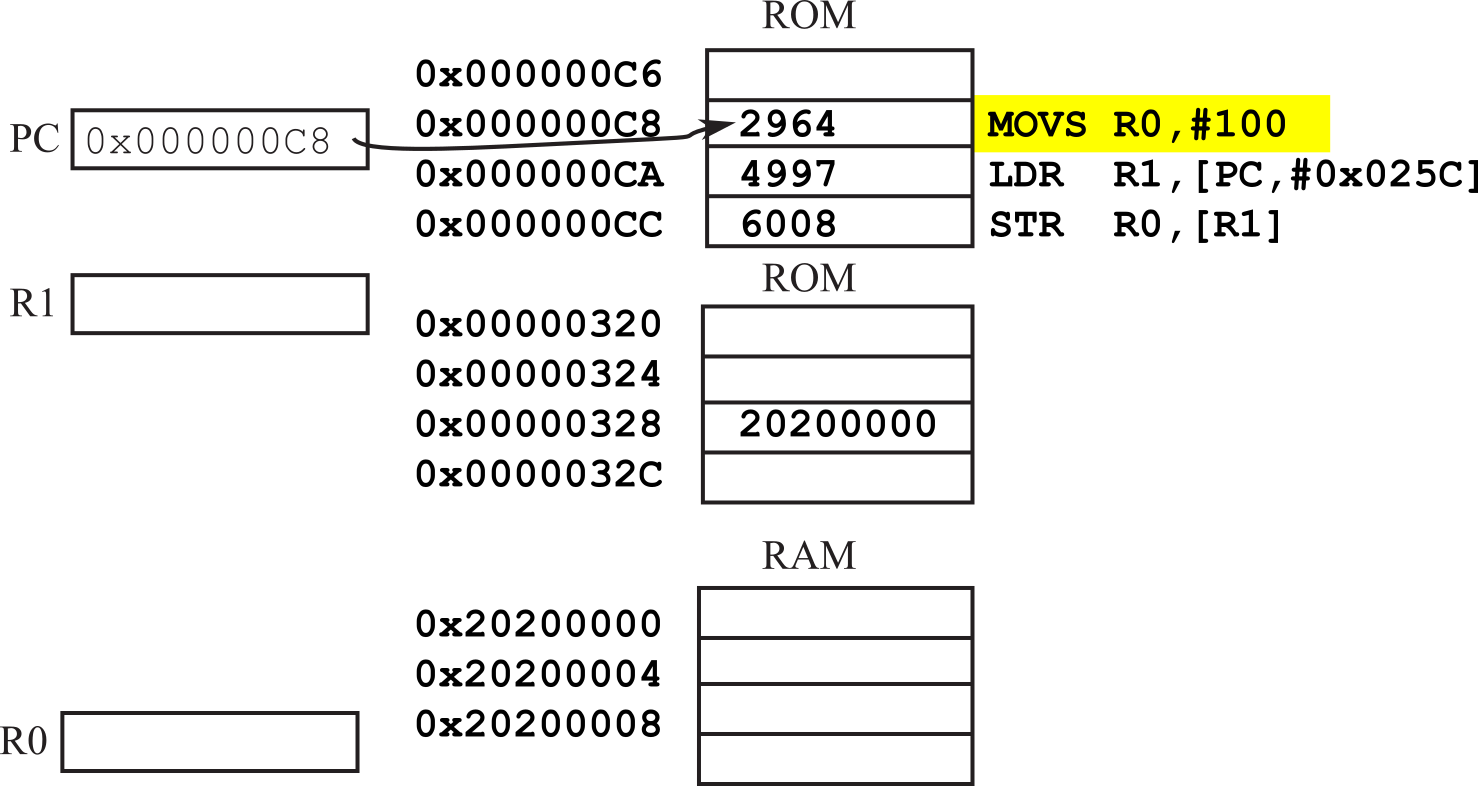
Figure 1.7.5. It takes three instructions to write to a global variable.
: How would you modify the above assembly code to write 0x0E to Port A output?
To read the value of a variable into a register
will take two instructions. After executing these two instructions, R3
will have a copy of the value from the global Stuff. The first LDR
instruction sets R2 to point to the global variable Stuff.
The second LDR instruction will read the value from the
variable.
LDR R2,=Stuff // R2 points to the variable Stuff
LDR R3,[R2] // R3=Stuff
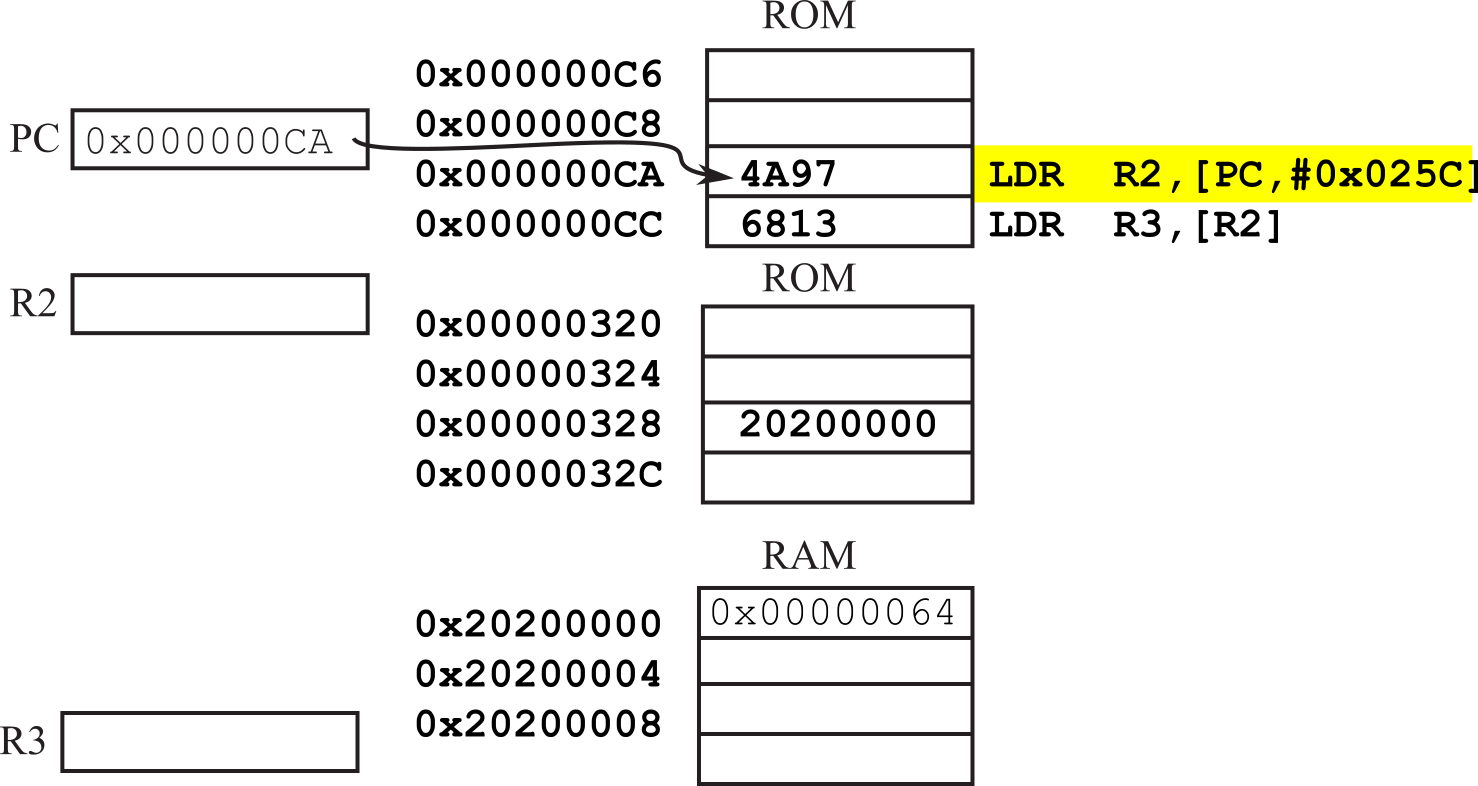
Figure 1.7.6. It takes two instructions to read from a global variable.
: How would you modify the above assembly code to read from Port A input?
An aligned access is an operation where a word-aligned address is used for a word, dual word, or multiple word access, or where a halfword-aligned address is used for a halfword access. Byte accesses are always aligned. The address of an aligned word access will have its bottom two bits equal to zero. An unaligned word access means we are accessing a 32-bit object (4 bytes) but the address is not evenly divisible by 4. The following instructions support 32-bit memory access:
LDR Load 32-bit word
STR Store 32-bit word
Observation: 32-bit accesses using LDR and STR must be to word-aligned addresses.
The address of an aligned halfword access will have its bottom bit equal to zero. An unaligned halfword access means we are accessing a 16-bit object (2 bytes) but the address is not evenly divisible by 2. The following instructions support 16-bit memory access:
LDRH Load 16-bit unsigned halfword
LDRSH Load 16-bit signed halfword (sign extend bit 15 to bits 31-16)
STRH Store 16-bit halfword
Observation: 16-bit accesses using LDRH LSRSH and STRH must be to halfword-aligned addresses.
Transfers of one byte are allowed for the following instructions:
LDRB Load 8-bit unsigned byte
LDRSB Load 8-bit signed byte (sign extend bit 7 to bits 31-8)
STRB Store 8-bit byte
When loading a 32-bit register with an 8- or 16-bit value, it is important to use the proper load, depending on whether the number being loaded is signed or unsigned. This determines what is loaded into the most significant bits of the register to ensure that the number keeps the same value when it is promoted to 32 bits. When loading an 8-bit unsigned number, the top 24 bits of the register will become zero. When loading an 8-bit signed number, the top 24 bits of the register will match bit 7 of the memory data (signed extend). Note that there is no such thing as a signed or unsigned store. For example, there is no STRSH; there is only STRH. This is because 8, 16, or all 32 bits of the register are stored to an 8-, 16-, or 32-bit location, respectively. No promotion occurs. This means that the value stored to memory can be different from the value located in the register if there is overflow. When using STRB to store an 8-bit number, be sure that the number in the register is 8 bits or less.
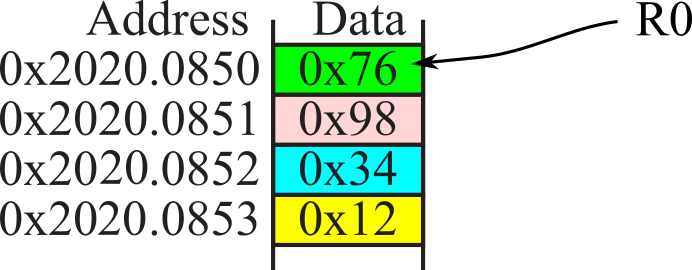
Figure 1.7.6. Assume these memory contents for Checkpoints 1.7.5 through 1.7.9.
: Assume R0 equals 0x20200850 at the time LDR R1,[R0] is executed. To what value will R1 become?
: Assume R0 equals 0x20200850 at the time LDRH R2,[R0] is executed. To what value will R2 become?
: Assume R2 equals 0 and R0 equals 0x20200850 at the time LDRSH R3,[R0,R2] is executed. To what value will R3 become?
: Assume R0 equal 0x20200850 at the time LDRB R4,[R0] is executed. To what value will R4 become?
: Assume R2 equals 0 and R0 equals 0x20200850 at the time LDRSB R5,[R0,R2] is executed. To what value will R5 become?
1.7.4. Logical Operations
Boolean Logic has two states: true (1) and false (0). A binary operation produces a single result given two inputs. The logical and (&) operation yields a true result if both input parameters are true. The logical or (|) operation yields a true result if either input parameter is true. The exclusive or (^) operation yields a true result if exactly one input parameter is true. The logical operators are summarized in the table below. The logical instructions on the ARM Cortex-M processor take two inputs, one from a register and the other either from a register or from a constant. These operations are performed in a bit-wise fashion on two 32-bit input parameters yielding one 32-bit output result. The result is stored into the destination register. For example, the calculation r=m&n means each bit is calculated separately, r31=m31&n31, r30=m30&n30,..., r0=m0&n0.
In C, when we write logical operations as
r=m&n; r=m|n; r=m^n; the logical operation occurs in a bit-wise
fashion also described by the table below. However, in C, we define the
Boolean functions as r=m&&n; r=m||n; For Booleans, the operation
occurs in a word-wise fashion. For example, r=m&&n; means r will
become zero if either m is zero or n is zero. Conversely, r will become
1 (any nonzero) if both m is nonzero and n is nonzero.
| A | B | A&B | A|B | A^B | A&(~B) |
| Rn | Op2 | AND | ORR | EOR | BIC |
| 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 1 | 1 | 0 |
| 1 | 0 | 0 | 1 | 1 | 1 |
| 1 | 1 | 1 | 1 | 0 | 0 |
Table 1.7.1. Logical operations performed by the Cortex-M processor.
All instructions place the result into the
destination register Rd. If Rd is omitted, the result
is placed into Rn, which is the register holding the first
operand. The N and Z condition code
bits are updated on the result of the operation. The second operand is
a register. We use the ANDS instruction
to mask or select bits. We use the ORRS instruction to set bits.
We use the EORSinstruction to toggle bits (change from 0 to 1
or 1 to 0) bits. We use the BICS instruction to clear bits.
ANDS Rd, Rn, Rm // Rd=Rn&Rm
ORRS Rd, Rn, Rm // Rd=Rn|Rm
EORS Rd, Rn, Rm // Rd=Rn^Rm
BICS Rd, Rn, Rm // Rd=Rn&(~Rm)
Assume Port B bit 1 (PB1) is an output. Writing to the
GPIOB_DOUT31_0 register performs output to general purpose
input/output pins on Port B. Reading from GPIOB_DOUT31_0
returns the previous value written to this register.
The
following example sets the PB1 pin high. Notice that this code will
leave the other pins unchanged.
// assembly version
LDR R0,=GPIOB_DOUT31_0 // pointer to output register
LDR R1,[R0] // previous values
MOVS
R2,#0x02 //
mask for bit 1
ORRS
R1,R1,R2 //
set bit 1
STR
R1,[R0]
// change actual output
// C version
GPIOB->DOUT31_0
= GPIOB->DOUT31_0 | 0x02;
Again, assume Port B bit 1 (PB1) is an output. The
following example clears the PB1 pin low, without changing any other
pins.
// assembly version
LDR R0,=GPIOB_DOUT31_0 // pointer to output register
LDR R1,[R0]
// previous values
MOVS R2,#0x02
// mask for bit 1
BICS R1,R1,R2
// clear bit 1
STR
R1,[R0]
// change actual output
// C version
GPIOB->DOUT31_0 = GPIOB->DOUT31_0 & ~0x02;
: How would you change the above program to set the PB3 pin?
: How would you change the above program to toggle the PB2 pin?
1.7.5. Shift Operations
Like programming in C, the assembly shift instructions take two input parameters and yield one output result. In C, the left shift operator is << and the right shift operator is >>. E.g., to left shift the value in m by n bits and store the result in r we execute: r = m<<n. Similarly, to right shift the value in m by n bits and store result r, we execute: r=m>>n.
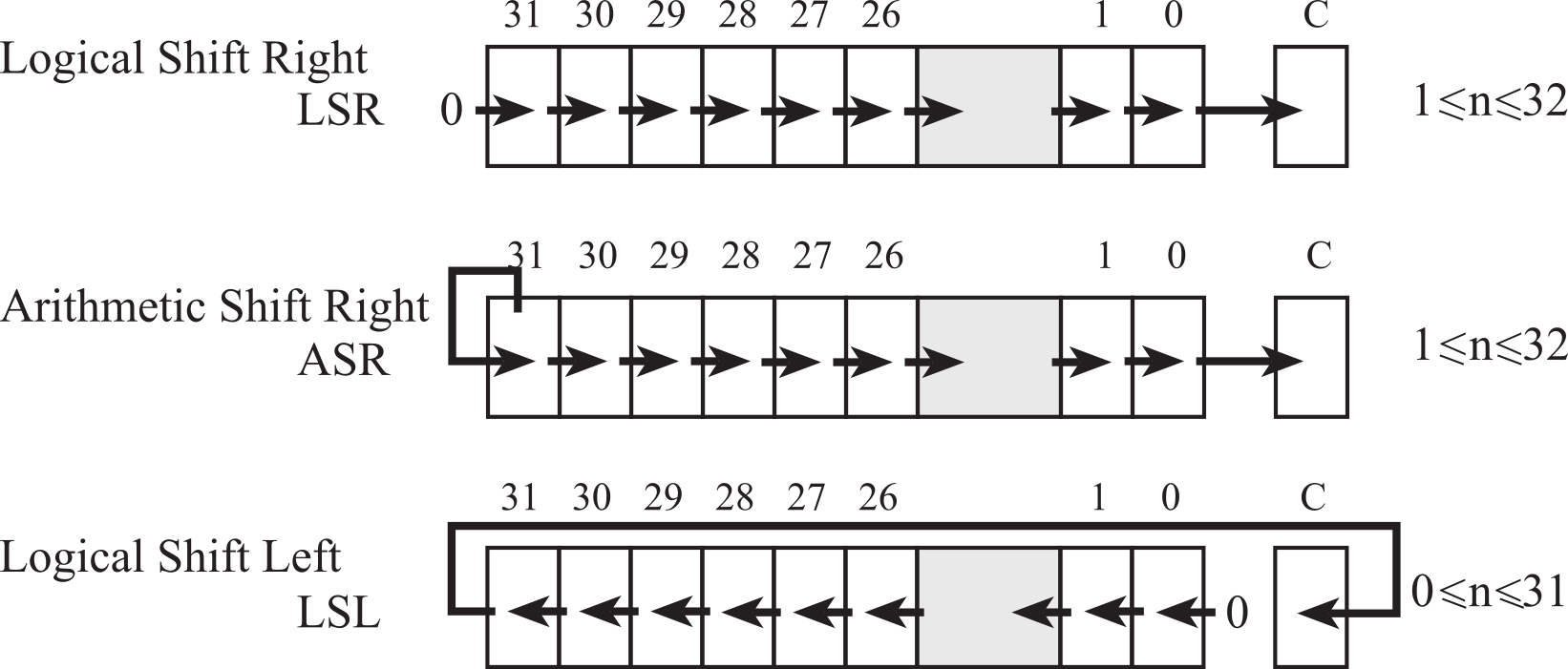
Figure 1.7.7. Shift operations move bits to the right or left.
The logical shift right (LSRS) is similar to an unsigned divide by 2n, where n is the number of bits shifted. A zero is shifted into the most significant position, and the carry flag will hold the last bit shifted out. The right shift operations do not round. For example, a right shift by 3 bits is similar to divide by 8. However, 15 right-shifted three times (15>>3) is 1, while 15/8 is much closer to 2. In general, the LSR discards bits shifted out.
The arithmetic shift right (ASRS) is similar to a signed divide by 2n. Notice that the sign bit is preserved, and the carry flag will hold the last bit shifted out. This right shift operation also does not round. Again, a right shift by 3 bits is similar to divide by 8. However, -9 right-shifted three times (-9>>3) is -2, while implementing -9 divided by 8 using the SDIV instruction yields -1. In general, the ASR discards bits shifted out, and the SDIV truncates towards 0.
The logical shift left (LSLS) operation works for both unsigned and signed multiply by 2n. A zero is shifted into the least significant position, and the carry bit will contain the last bit that was shifted out.
All shift instructions place the result into the destination register Rd. Rm is the register holding the value to be shifted. The number of bits to shift is either in register Rs, or specified as a constant n. The N and Z condition code bits are updated on the result of the operation. The C bit is the carry out after the shift. These shift instructions will leave the V bit unchanged.
Observation: Use logic shift for unsigned numbers and arithmetic shifts for signed numbers.
LSRS Rd, Rm, Rs // logical shift right
Rd=Rm>>Rs (unsigned)
LSRS Rd, Rm, #n // logical shift right
Rd=Rm>>n (unsigned)
ASRS Rd, Rm, Rs // arithmetic shift right
Rd=Rm>>Rs (signed)
ASRS Rd, Rm, #n // arithmetic shift right
Rd=Rm>>n (signed)
LSLS Rd, Rm, Rs // shift left Rd=Rm<<Rs
(signed, unsigned)
LSLS Rd, Rm, #n // shift left Rd=Rm<<n
(signed, unsigned)
: If R0=0xC0123456, what will be the value in R0 after LSRS R0,R0,#4 is executed?
: If R0=0xC0123456, what will be the value in R0 after ASRS R0,R0,#4 is executed?
: If R0=0xC0123456, what will be the value in R0 after LSLS R0,R0,#4 is executed?
1.7.6. Arithmetic Operations
When software executes arithmetic instructions, the operations are performed by digital hardware inside the processor. Even though the design of such logic is complex, we will present a brief introduction, in order to provide a little insight as to how the computer performs arithmetic. It is important to remember that arithmetic operations (addition, subtraction, multiplication, and division) have constraints when performed with finite precision on a processor. An overflow error occurs when the result of an arithmetic operation cannot fit into the finite precision of the register into which the result is to be stored. The N C V and Z condition code bits are updated on the result of the operation.
The immediate value #n can be any 8-bit unsigned constant.
When Rd is absent, the result is placed back in Rn.
ADDS Rd, Rn, Rm // Rd = Rn + Rm
ADDS Rd, Rn, #n // Rd = Rn + n
SUBS Rd, Rn, Rm // Rd = Rn - Rm
SUBS Rd, Rn, #n // Rd = Rn - n
CMP Rn, Rm // Rn - Rm
CMP Rn, #n // Rn - n
The addition and subtraction instructions set the condition code bits as shown in the following table. The addition and subtraction instructions work for both signed and unsigned values. As designers, we must know in advance whether we have signed or unsigned numbers. The computer cannot tell from the binary which type it is, so it sets both C and V. Our job as programmers is to look at the C bit if the values are unsigned and look at the V bit if the values are signed.
| Bit | Name | Meaning after addition or subtraction |
| N | Negative | Result is negative |
| Z | Zero | Result is zero |
| V | Overflow | Signed overflow |
| C | Carry | Unsigned overflow |
Table 1.7.2. Condition code bits contain the status of the previous arithmetic operation.
Observation: The carry bit, C, is set after an unsigned addition when the result is incorrect. The carry bit, C, is cleared after an unsigned subtraction when the result is incorrect.
Observation: The overflow bit, V, is set after a signed addition or subtraction when the result is incorrect.
1.7.7. Multiply and Divide
To understand the multiplication algorithm, consider these two assembly functions that multiply two 8-bit unsigned integers, A and B, yielding a 16-bit result, R. In general, an n-bit number multiplied by an m-bit number yields an (n+m)-bit product. The slow algorithm, initializes R=0, and then adds R=R+A, B times. The slow algorithm is simple to understand, but very slow. In particular, if B is 255, then this algorithm requires 4*255+3=1023 instructions to complete. If we assume B is uniformly and randomly distributed from 0 to 255, this algorithm requires 4*128+3=515 instructions to complete. The fast algorithm is designed with the basis elements of a binary number in mind. If bit n of A is set, then R=R+2n*B. We initialize a loop counter at 8 because the multiplier is 8 bits, the product is initially 0. The LSRS instruction shifts the least significant bit into the carry, deciding whether or not the multiplier needs to be added. Each time through the loop the multiplier is shifted right and multiplicand is shifted left. This fast algorithm takes to 44 to 52 instructions to complete.
// Inputs: A=R0 is 8-bit unsigned
// B=R1 is 8-bit unsigned
// Output: R=A*B is 16-bit product
slowmul:
MOVS R2,#0 // R2 is result R
loop: CMP R1,#0 // quit when B=0
BEQ done
ADDS R2,R2,R0 // R=R+A
SUBS R1,R1,#1 // B=B-1
B loop
done: MOVS R0,R2 // result in R0
BX LR
// Inputs: A=R0 is 8-bit unsigned
// B=R1 is 8-bit unsigned
// Output: R=A*B is 16-bit product
fastmul:
MOVS R2,#8 // loop counter
MOVS R3,#0 // product
loop: LSRS R0,R0,#1 // check next bit in multiplier
BCC next // skip if bit is 0
ADDS R3,R1 // add multiplicand
next: LSLS R1,R1,#1 // next bit is twice the value
SUBS R2,R2,#1
BNE loop
MOVS R0,R3 // product
BX LR
Program 1.7.1. Two multiply algorithms.
Next, let's convert Program 1.7.1 to multiply two 16-bit unsigned integers. The same code on the left operates for any size inputs up to 32 bits (neither algorithm checks for overflow). To change the code on the right to 16 by 16, we simply change the loop counter to 16. If B is 65535, then the left algorithm requires 4*65535+3=262140 instructions to complete (256 times slower). However, for the fast algorithm, because the loop counter is doubled, it only runs twice as slow. If n is the number of bits in the number, the slow algorithm takes on the order of 2n instructions, while the fast algorithm takes on the order of n instructions.
Observation: Choosing a good algorithm can have a profound impact on performaance.
Multiply (MULS) uses 32-bit operands and
produces a 32-bit result. This multiply instruction only saves the
bottom 32 bits of the result. It can be used for either signed or
unsigned numbers, but no overflow flags are generated. If the Rd
register is omitted, the Rn register is the destination. The MULS
does set the Z and N bits according to the
result.
MULS Rd, Rd, Rm // Rd = Rd * Rm
: If one adds an n-bit number to another n-bit number, how many total bits are in the sum?
: If one multiplies an n-bit number to an m-bit number, how many total bits are in the product?
The Cortex M0+ does not have a division instruction. So, to divide we will need to implement the operation as a function. Consider these two assembly functions that divide a 32-bit unsigned dividend, A by a 16-bit unsigned divisor, B, yielding a 16-bit quotient, Q and a 16-bit remainder R. Notice that both these algorithms return two values (R0, R1), and therefore are not AAPCS compliant. The definition of unsigned divide is
A = Q*B+R assuming R<B
The slow algorithm counts how many times we can subtract the divisor from the dividend. It is easy to understand, but very slow. If the dividend is 65535 and the divisor is 1, the slow algorithm requires 65535*5+4=327679 instructions to execute. The fast algorithm is designed with the basis elements of a binary number in mind, modeled after how we perform long division. We left shift the divisor under the dividend as many times as we can while the shifted divisor is less than the dividend. We then set the bit in the quotient and subtract the shifted divisor from the dividend. The fast algorithm takes from 105 to 127 instructions to complete.
// Inputs: A=R0 is 32-bit unsigned dividend
// B=R1 is 16-bit unsigned divisor
// Outputs: Q=A/B is 16-bit quotient
// B=R1 is 16-bit remainder
slowdiv: // R0 becomes the remainder, R
MOVS R2,#0 // R2 is quotient Q
loop: CMP R0,R1 // quit when R<B
BLO done
ADDS R2,R2,#1 // Q=Q+1
SUBS R0,R0,R1 // A=A-B
B loop
done: MOVS R1,R0 // remainder in R1
MOVS R0,R2 // quotient in R0
BX LR
// Inputs: A=R0 is 32-bit unsigned dividend
// B=R1 is 16-bit unsigned divisor
// Outputs: Q=A/B is 16-bit quotient
// B=R1 is 16-bit remainder
fastdiv:
PUSH {R4,LR}
LDR R4,=0x00010000 // bit mask
MOVS R3,#0 // quotient
MOVS R2,#16 // loop counter
LSLS R1,#15 // move divisor under dividend
loop: LSRS R4,R4,#1 // bit mask 15 to 0
CMP R0,R1 // need to subtract?
BLO next
SUBS R0,R0,R1 // subtract divisor
ORRS R3,R3,R4 // set bit
next: LSRS R1,R1,#1
SUBS R2,R2,#1
BNE loop
MOVS R1,R0 // remainder
MOVS R0,R3 // quotient
POP {R4,PC}
Program 1.7.2. Two divide algorithms.
Observation: You will use the fast divide algorithm in Lab 6 to convert an integer into a sequence of ASCII characters by dividing the integer by 10, and using both the quotient and remainder.
Observation: The MSPM0G3507 has a hardware accelerator capable of multiply, divide, sine, cosine, arctan, and square root. See the MATHACL chapter in the Technical Reference Manual.
Quiz 1.7
1.8. Flowcharts, Structured Programming and Conditional Statements
In this course we will construct software using only three basic building blocks: sequence, conditional, and loop. There are two conditionals (if-then and if-then-else) and two loops (while-loop and do-while-loop), see Figure 1.8.1. We will use the conditional branch instructions to create this software block.
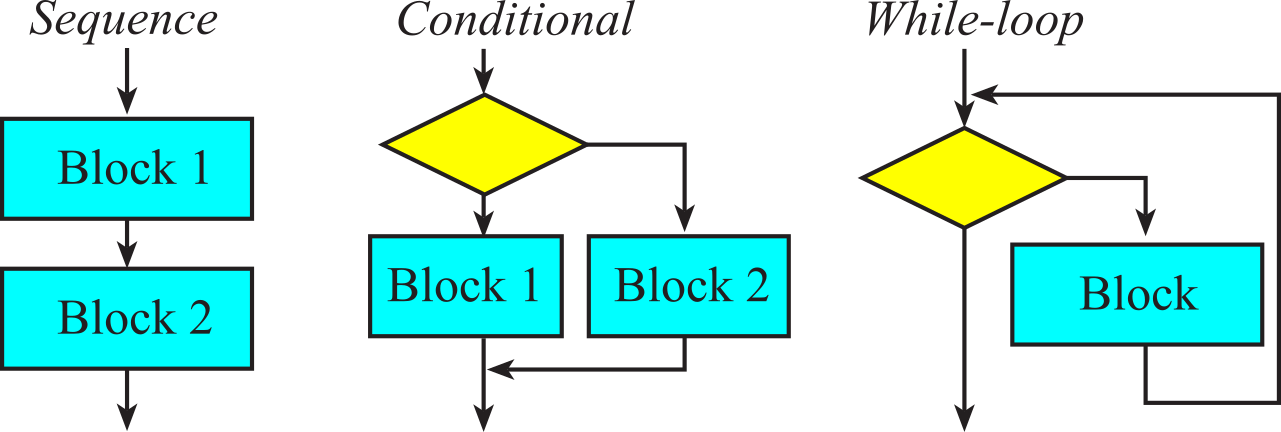
Figure 1.8.1. Structured programming uses these three basic structures.
Normally the computer executes one instruction
after another in a linear fashion, which constitutes the sequence. In particular, the next instruction
to execute is found immediately following the current instruction. We
use branch instructions to deviate from this straight line path,
creating the conditional and the loop. The
following lists a few of the many branch instructions. The conditional
branching must be preceded by an instruction that sets the condition
code bits.
B label // unconditional
branch to label
BEQ label // branch to label if Z=1
BNE label // branch to label if Z=0
BMI label // branch to label if N=1
BPL label // branch to label if N=0
BCS label // branch to label if C=1
BCC label // branch to label if C=0
BVS label // branch to label if V=1
BVC label // branch to label if V=0
One of the ways we affect execution flow is the conditional. To compare two values, they must be the same type.
First, we present an approach to conditionally test for individual bits.
Let mask specify which bit to test. For example, to test bit 3, we set the mask to 0x08.
In general the mask for bit n is 1<<n.
The approach is
Bring the entire value into R0
Bring the 1<<n mask value into R1
Check for bit n using ANDS R0,R0,R1
Execute one of the following conditionals
BEQ target // Branch if R0 bit n is 0
BNE target // Branch if R0 bit n is 1
To illustrate the conditional, let's write software that sets bit 1 of variable V1 to 1 if bit 8 of variable V0 is set, see Figure 1.8.2 and Program 1.8.1. Notice, we skip over the body if bit 8 is clear.
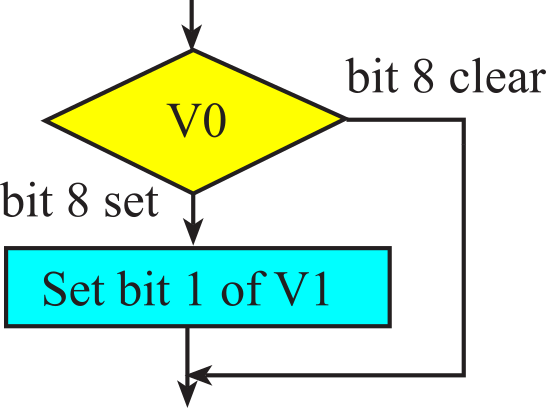
Figure 1.8.2. Flowchart of a conditional statement.
For the assembly implementation, we assume variable V0 is in register R0 and V1 is in register R1. The mask for bit 8 is 0x0100. The assembly version destroys R2 R3.
|
LDR R2,=0x0100 ANDS R2,R2,R0 BEQ next MOVS R2,#0x02 // mask for set bit 1 ORRS R1,R1,R2 // set bit 1 next: |
if((V0&0x0100) == 0x0100{ V1 |= 0x02; } |
Program 1.8.1. Conditional to test individual bits.
To illustrate the loop, we will implement a simple unsigned multiply, see Figure 1.8.3 and Program 1.8.2. We assume R0(n0) and R1(n1) are the inputs and function will perform R0*R1, placing the product in R2(n2). We initialize a sum in R2, which will be converted to the product. In a while-loop the ending condition is tested before the loop statement. This is necessary because R1 might be 0, meaning the loop statement should never be executed. During each loop statement, R0 is added to R2, and R1 is decremented.
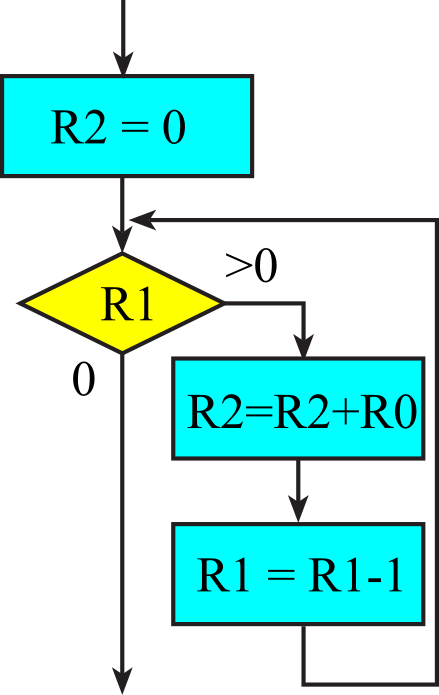
Figure 1.8.3. Flowchart of a loop structure.
|
MOVS R2,#0 // sum |
sum = 0; |
Program 1.8.2. While-loop to implement multiply.
Next, we
present if-then for signed 32-bit integers. The approach is
Bring the first value into R0
Bring the second value into R1
Compare the two values using CMP R0,R1
Execute one of the following signed conditionals
BEQ target // Branch if R0 equals R1
BNE target // Branch if R0 does not
equal R1
BLT target // Branch if R0 is less than
R1 (signed)
BLE target // Branch if R0 is less than
or equal to R1 (signed)
BGE target // Branch if R0 is greater
than or equal to R1 (signed)
BGT target // Branch if R0 is greater
than R1 (signed)
The approach is similar when comparing two unsigned
32-bit integers
Bring the first value into R0
Bring the second value into R1
Compare the two values using CMP R0,R1
Execute one of the following unsigned
conditionals
BEQ target // Branch if R0 equals R1
BNE target // Branch if R0 does not
equal R1
BLO target // Branch if R0 is less than
R1 (unsigned)
BLS target // Branch if R0 is less than
or equal to R1 (unsigned)
BHS target // Branch if R0 is greater
than or equal to R1 (unsigned)
BHI target // Branch if R0 is greater
than R1 (unsigned)
Quiz 1.8
1.9. Stack and functions
As our software becoming more complex, we will need
to create functions. The SP points to data on the top of the stack.
We use push to save data and pop to retrieve data. The stack operates in a
last in first out manner. Let's present rules for using the stack
1. Functions should have an equal number of
pushes and pops
2. Stack accesses should not be performed
outside the allocated area
3. Stack reads and writes should not be
performed within the free area
4. Stack push should first decrement SP,
then store the data
5. Stack pop should first read the data,
and then increment
The stack grows downwards in memory as we push data on to it so, although
we refer to the most recent item as the “top of the stack” it
is actually the item stored at the lowest address! To push data
on the stack, the stack pointer is first decremented by 4, and then the
32-bit information is stored at the address specified by SP. To pop data
from the stack, the 32-bit information pointed to by SP is first
retrieved, and then the stack pointer is incremented by 4. SP points to
the last item pushed, which will also be the next item to be popped. The
boxes in Figure 1.9.1 represent 32-bit storage elements in RAM. The grey
boxes in the figure refer to actual data stored on the stack, and the
white boxes refer to locations in the stack area, but do not contain stack
data. This figure illustrates how the stack is used to push the contents
of Registers R0, R1, and R2 in that order. Assume Register R0 initially
contains the value 1, R1 contains 2, and R2 contains 3. The drawing on the
left shows the initial stack. The software executes these six instructions
in this order:
PUSH {R0}
PUSH {R1}
PUSH {R2}
POP {R3}
POP {R4}
POP {R5}
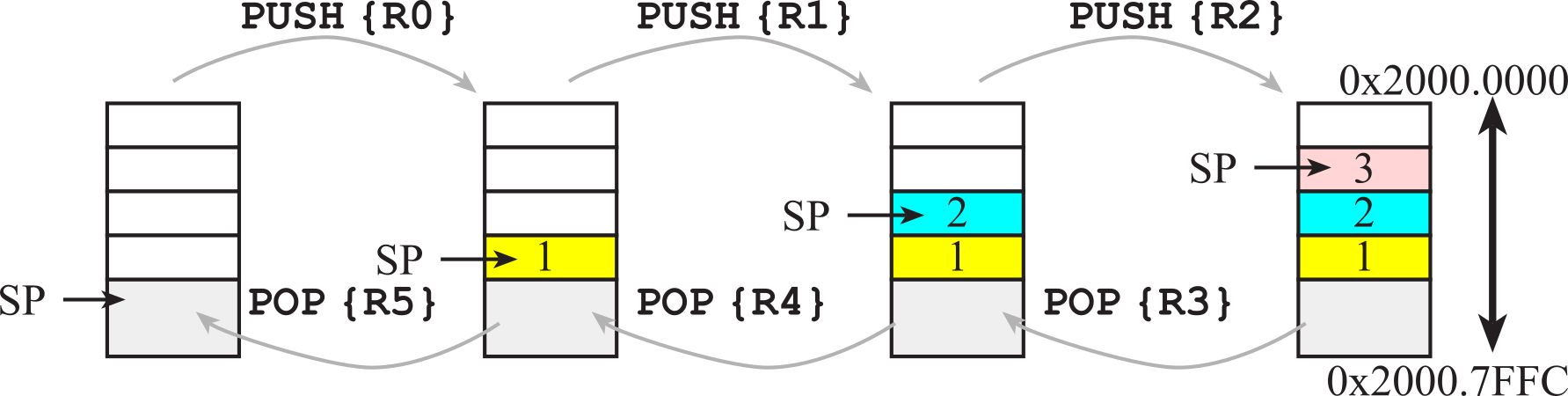
Figure 1.9.1. Stack picture showing three numbers first being pushed, then three numbers being popped. You are allowed to draw stack pictures so that the lowest address is on the top (like this one) or so that lowest address is on the bottom. It is important however to be clear, accurate, and consistent.
Remember the order in the register list does not matter. The register with the lower number is stored in memory with the lower address. These are the same instructions
PUSH {R2,R5}
PUSH {R5,R2}
We use the BL instruction to call a subroutine. The BL instruction will save the return address in LR, which will be the address of the instruction after the BL,and branch to the subroutine. The BX LR will return the LR back into the PC, causing control flow to revert back to the place from which the function was called. If one function calls another it will need to save the LR on the stack.
In
general we will adhere to the following rules according to ARM
Architecture Procedure Call Standard (AAPCS). The
Caller is the software executing the BL instruction, and
the Callee is the subroutine. AAPCS means the caller and callee
agree to these five rules:
1) The input parameters, if any, are in R0-R3,
2) The output parameter, if exists, is in R0,
3) The callee saves, uses, and restores R4-R11,
4) The callee balances the stack,
5) The caller cannot assume R0-R3,R12 will be preserved.
Because of these rules, we classify R0-R3 as argument registers, and we classify R4-R11 as local registers. We normally do not use R12 on the Cortex M0, but if we were to use it, it is classified as a free register. The callee can freely use R0-R3,R12 without needing to push or pop. The callee can use R4-R11 but must push the values at the start and pop the values at then end.
Program 1.9.1 illustrates
one function calling another. The interesting part
is that (in assembly) after the operations within the subroutine are
performed, control returns to the place right after where the subroutine
was called. It is the same in C. You will also see how the registers are
manipulated as the code flows.
| Assembly Code | Registers | ||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Address Machine Code Label Instruction Comment 0x000000C0 3002 Fun2: ADDS R0,#2 // x=x+2 0x000000C2 4770 BX LR // return x 0x000000C4 B500 Fun1: PUSH {LR} 0x000000C6 FFFBF7FF BL Fun2 // y=Fun2(y) 0x000000CA BD00 POP {PC} // return y 0x000000CC 2001 main: MOVS R0,#1 // z=1 0x000000CE FFF9F7FF loop: BL Fun1 // z=Fun1(z) 0x000000D2 E7FC B loop |
|
||||||||||||||||||||||||||||||||
| C Code | |||||||||||||||||||||||||||||||||
|
int32_t Fun2(int32_t x){ x = x+2; return(x); } int32_t Fun1(int32_t y){ y = Fun2(y); return(y); } void main(void){ int32_t z; z = 1; while(1){ z = Fun1(z); } } |
Program 1.9.1. A function with two inputs and one output.
There are two aspects of a function in assembly. First the aspect is the definition. The first three lines of Program 1.9.2 are comments, which explain what the function does. The explanation describes the input parameters and output parameter. Line 4 creates an assembly label specifying the entry point of the function. In this example, lines 5 and 6 perform the body of the function. Comments inside the body should explain how the function works. Line 7 is the function return using the BX LR instruction. Figure 1.9.2 shows the flowchart syntax for a function
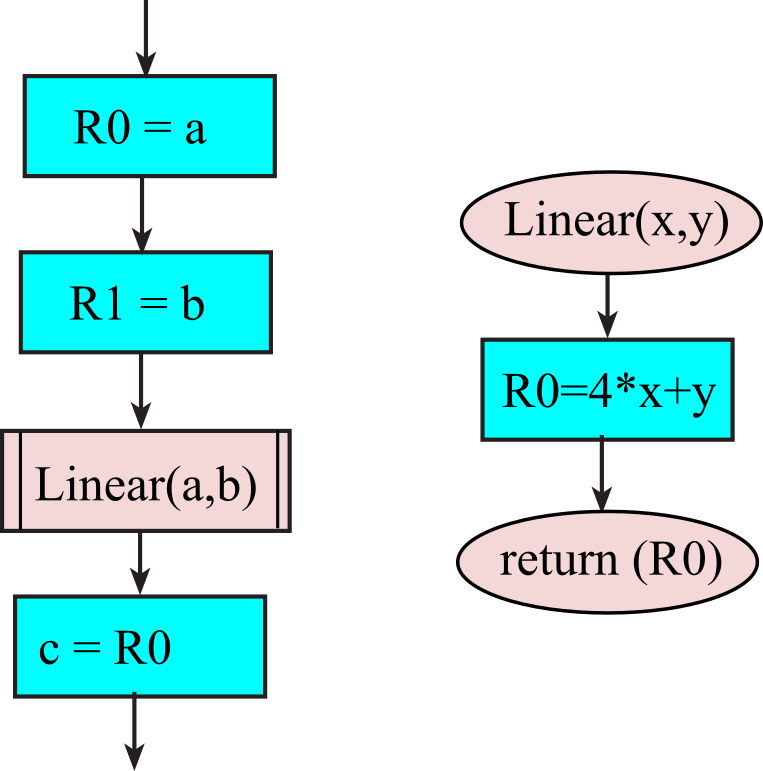
Figure 1.9.2. Flowchart of a function; left is function invocation, right is the function definition.
|
// Inputs: x in R0 1 |
uint32_t Linear(uint32_t x, uint32_t y){ return (x<<2)+y; } |
Program 1.9.2. Function definition in both assembly and C.
Second the aspect is the invocation. Before we invoke a function, we establish the input parameters. Assume a,b,c are global variables. Lines 8-11 set the input parameters R0 to a and R1 to b. Line 12 is the invocation using the BL instruction. After the function returns, we process the output result. In this case, the result is stored in c. The overall effect is to implement c=4*a+b
|
LDR R0,=a // 8 |
|
Program 1.9.2. Function invocation both in assembly and assembly.
Functions are so important, let's do another example. We define a subroutine by giving it a name in the label field, followed by instructions, which when executed, perform the desired effect. The last instruction in a subroutine will be BX LR, which we use to return from the subroutine. In Program 1.9.3, we define the subroutine named Random, which returns a random number from 0 to 255. The flowchart for this example is drawn in Figure 1.9.3.
Figure 1.9.3. Flowchart of a function; left is function invocation, right is the function definition.
|
.data |
uint32_t M; uint32_t Random(void){ M = 1664525*M +1013904223; return M>>24; } |
Program 1.9.3. Function definition in both assembly and C.
In assembly language, we will use the BL instruction to call this subroutine, see Program 1.9.4. At run time, the BL instruction will save the return address in the LR register. The return address is the location of the instruction immediately after the BL instruction. At the end of the subroutine, the BX LR instruction will retrieve the return address from the LR register, returning the program to the place from which the subroutine was called. More precisely, it returns to the instruction immediately after the instruction that performed the subroutine call. The comments specify the order of execution. The while-loop causes instructions 4–15 to be repeated over and over.
|
.text |
int main(void){ uint32_t x; M = 0; while(1){ x = Random(); } } |
Program 1.9.3. Function definition in both assembly and C.
: What happens to the LR when the BL instruction is executed?
: How does the BX LR instruction return from the function?
: What must you do if one function calls another function?
Quiz 1.9
1.10. Introduction to Data Structures
The organization of data has a significant impact on the effectiveness of any computer system. A data structure defines how data are organized. In this section, we present three data structures: array, string, and linked list. Arrays and strings store multiple elements of the same type. The linked list is a flexible data structure we can use to associate multiple elements of different types. Each node of a linked list has information and a pointer (link) to the next node of the list. The focus of Chapter 1 is assembly language, but we include C versions to help explain the assembly code.
Random access means one can read and write any element in any order. Random access is allowed for all indexable data structures.
Sequential access means one reads and writes the elements in order. Pointers are usually employed in these types of data structures. Linked lists, stacks, queues, and trees are examples of sequential structures. The first in first out circular queue (FIFO) is useful for data flow problems, and it will be presented in Chapter 8.
An array is a collection of elements of the same data type that share a single name. In C, the individual elements of an array are referenced by appending a subscript, in square brackets, behind the name. The subscript itself can be any legitimate C expression that evaluates to an integer. Although an array represents one of the simplest data structures, it has wide-spread usage in embedded systems. In assembly, we declare arrays in a manner similar to declaring variables, except we specify the total size in bytes. The precision is the size of each element, defined by the data type. In Program 1.11.1, the precision is 4 bytes. In assembly, the .data specifies the array goes in RAM. The .space declaration allocates 20 bytes of space, which in this instance hold an array of five 32-bit signed integers (5x4=20 bytes) with the name Data.
Figure 1.10.1. An array with 5 elements.
|
.data |
|
Program 1.10.1. An array with 5 elements.
In general, let n be the precision of a zero-origin indexed array in bytes. If I is the index and Base is the beginning address of the array, then the address of the element at I is
Base+n*I
The American Standard Code for Information Interchange (ASCII) is a standard format for storing characters, see Table 1.10.1. A string is an array of 8-bit ASCII characters. The characters of the string are typically read in order from the first to the last. ASCII strings are stored with null-termination. The null character (0) is called a sentinel. From a programming perspective we access strings in the same manner as arrays. In particular, we can access using pointers or indices. When defining a constant string, the compiler knows the length, and it can allocate the appropriate space for the characters plus the null. In the previous constant arrays, we specified the size; however for strings the size can be left off and the compiler/assembler will calculate the size automatically. In assembly, and with the .string directive, the assembler automatically adds the zero at the end. Program 1.10.2 and Figure 1.10.2 define a constant string of ASCII characters with null termination.
BITS
4 to 6
|
|
|
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
|
|
0 |
NUL |
DLE |
SP |
0 |
@ |
P |
` |
p |
|
B |
1 |
SOH |
XON |
! |
1 |
A |
Q |
a |
q |
|
I |
2 |
STX |
DC2 |
" |
2 |
B |
R |
b |
r |
|
T |
3 |
ETX |
XOFF |
# |
3 |
C |
S |
c |
s |
|
S |
4 |
EOT |
DC4 |
$ |
4 |
D |
T |
d |
t |
|
|
5 |
ENQ |
NAK |
% |
5 |
E |
U |
e |
u |
|
0 |
6 |
ACK |
SYN |
& |
6 |
F |
V |
f |
v |
|
|
7 |
BEL |
ETB |
' |
7 |
G |
W |
g |
w |
|
T |
8 |
BS |
CAN |
( |
8 |
H |
X |
h |
x |
|
O |
9 |
HT |
EM |
) |
9 |
I |
Y |
i |
y |
|
|
A |
LF |
SUB |
* |
: |
J |
Z |
j |
z |
|
3 |
B |
VT |
ESC |
+ |
; |
K |
[ |
k |
{ |
|
|
C |
FF |
FS |
, |
< |
L |
\ |
l |
| |
|
|
D |
CR |
GS |
- |
= |
M |
] |
m |
} |
|
|
E |
SO |
RS |
. |
> |
N |
^ |
n |
~ |
|
|
F |
SI |
US |
/ |
? |
O |
_ |
o |
DEL |
Table 1.10.1. Standard 7-bit ASCII.
Figure 1.10.2. A string with seven characters will require eight bytes of storage.
|
.text |
const char Name[] = "ECE319K"; |
Program 1.10.2. Definition of a constant string.
We will work through a five step development process. The first step will be to define the problem. We will design a function that determines the length of a string. Strings are a sequence of characters terminated by a 0. Each character is 8 bits. We define length as the number of characters. E.g., the string in Figure 1.10.2 has length 7. The function will be passed a pointer to a string, and the result will be the length of the string. The string length could be 0. It is good design to think of how the function will be used before it is designed. In particular, we specify the name of the function, the inputs, and the outputs.
|
LDR R0,=Name |
uint32_t len; |
The second step will be pseudo code, which is a list of tasks to perform,
usually at a very high level. There is no specific syntax for pseudo code, but
often the pseudo code becomes comments for the actual code to be developed later.
We work through typical test cases by hand-executing the pseudo code. For example, this pseudo code
will return 0 for the string "", and will return 3 for the string "Jon".
1) Set a counter to 0
2) Fetch a character from the string
3) If the character is the null go to step 7
4) Increment the counter
5) Increment the pointer to the next character
6) Go to step 2
7) Return counter as the result
The third step will be a flowchart.
The numbers in Figure 1.10.3 correspond
to the pseudo code steps, showing you flowcharts and pseudo code present the same
information, just in a different format.
Figure 1.10.3.
A flowchart to determine the number of characters in a string. Observation: For simple problems like this we perform either the flowchart or the pseudo code,
with whichever you are most comfortable. However, in the early stages of developing your
skills in software design, we recommend you do both. The fourth step is to implement the software.
We convert the pseudo code to code. The pseudo code becomes comments for the code, see Program 1.10.3.
We cannot store strings themselves in registers, so we will pass a
pointer to the string in R0, and fetch data from the string one character at a time.
If R0 is a pointer to the first string, then LDRB R1,[R0] fetches the character at that address.
In C, if pt is a pointer to the first string, then *pt fetches the character at that address.
To increment the pointer to the next character, we add 1, because each character is 1 byte.
The function will return the number of characters in the string, in R0.
// R0 -> the string
// pt is a pointer to string Program 1.10.3.
Function to count the number of characters in a string. The fifth step is to test the software.
For this step, we review step 1 and write code that mimics how the software will be used.
For safety critical systems, we should test our code with 100's of examples, but Program 1.10.4 shows three test cases.
.text
int l1,l2,l3; Program 1.10.4.
main program to test the StrLen function. Let's expand our idea of arrays from a collection
of primitive data-types (i.e, characters, .byte, .short, .long) to
composite user-defined data-types. Say we wanted to keep track of
students ids
and, scores on two different exams, one trivial way of doing this is to
create 3 arrays, one array for each of the attributes: an ID array, a
Exam1 array and a Exam2 array, see Figure 1.10.4. Figure 1.10.4.
A list is an array of structs. Each struct has multiple elements with different types. The code for declaring these arrays
would be as follows:
.text Note that the elements in the ID array are .long (32-bit) which was chosen to accommodate ids
that may be <= 232 -1. For exam elements, the data-type of .short (16-bit) accommodates scores
that may be <= 216 -1.
Also note that each array is terminated by a sentinel (-1). Now, given a student's ID (say 233), if one wants to find
their first exam score, one would navigate the ID array to find where (as in index)
in the ID array the student is (i.e., 2), and then use that index in the Exam1Array to find the corresponding score (i.e., 94).
This obviously is both unintuitive and inefficient. Instead, consider storing all related information for a specific student
in contiguous memory, that is, we view a student's information as a composite of three attributes: ID, Exam1 and Exam2.
The programming term used to describe such a composite data type is a record or a struct (in C) or object (in C++). A struct/record is a composite data-type containing multiple fields (aka attributes) each having its own data-type.
A list then is an array of such structs that are stored contiguously.
In Figure 1.10.5, each struct (a student record) has three fields: an ID, an Exam1
and an Exam2.
The first field is a 32-bit ID.
The second and third fields are 16-bit grades.
E.g., the student with ID=7 has an Exam1 of 96 and an Exam2 of 82.
Because each struct is 8 bytes, they can be stored contiguously.
The end of the list is signified by a ID value of -1, called a sentinel.
Program 1.10.5 defines this list in ROM.
The function ID2Exam1 takes an ID and looks up the corresponding student's Exam1 score.
If R1 points to a struct, then [R1,#0] accesses the ID,
[R1,#4] accesses Exam1, and [R1,#6] accesses Exam2.
The function iterates through the array of student records checking to see if the
current student's ID matches the ID of the student being looked up. If the sentinel is reached before finding a match,
the function returns a 0 in R0 to indicate failure, otherwise it returns the matching student's score in R0.
Notice that, as we move from one struct (student record) to the next, we increment the pointer (in R1) by 8,
which is the size of each struct.
Figure 1.10.5.
A list is an array of structs. Each struct has multiple elements with different types.
.text Program 1.10.5.
A list with four structs stored in ROM, the fifth struct is the sentinel. Quiz 1.10 The details of the labs can be found in GoogleDocs:
Go to Chapter 2: Interfacing to Switches and LEDs
This material was created to teach
ECE319K at the University of Texas at Austin Reprinted with approval from Introduction to Embedded Systems Using the MSPM0+, ISBN: 979-8852536594
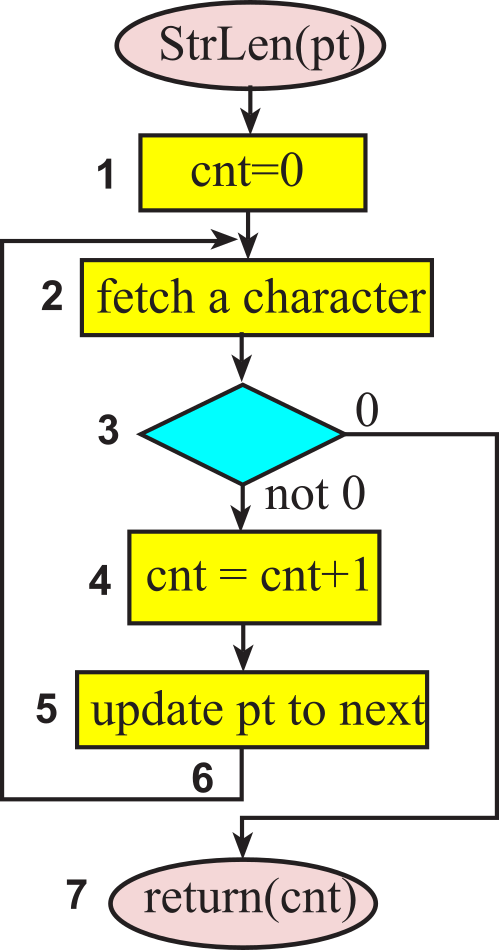
// return R0 as the length of string
// R0=0 means the string was empty
StrLen:
// 1) Set a counter to 0
MOVS R1,#0
// 2) Fetch a character from string
step2: LDRB R2,[R0] // *pt
// 3) If null go to step 7
CMP R2,#0
BEQ step7
// 4) Increment the counter
ADDS R1,#1
// 5) Increment the pointer to next
ADDS R0,#1
// 6) Go to step 2
B step2
// 7) Return counter as the result
step7: MOVS R0,R1
BX LR
// return length of the string
int StrLen(char *pt){
int cnt=0;
while((*pt) != 0){
cnt++;
pt++;
}
return cnt;
}
N1: .string "Ramesh"
N2: .string "Jon"
N3: .string ""
.align 2
main: LDR R0,=N1
BL StrLen
// we expect R0 to be 6
LDR R0,=N2
BL StrLen
// we expect R0 to be 3
LDR R0,=N3
BL StrLen
// we expect R0 to be 0
l1 = StrLen("Ramesh");
// we expect l1 to be 6
l2 = StrLen("Jon");
// we expect l2 to be 3
l3 = StrLen("");
// we expect l3 to be 0
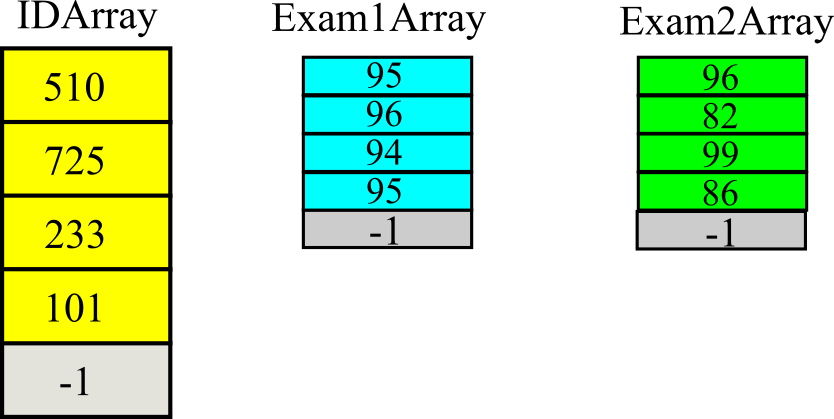
.align 2
IdArray: .long 510 // First student ID
.long 725
.long 233
.long 101
.long -1 // sentinel
Exam1Array: .long 95 // First student's first exam
.short 96
.short 94
.short 95
.short -1 // sentinel
Exam2Array: .short 96 // First student's second exam
.short 82
.short 99
.short 86
.short -1 // sentinel

.align 2
List: .long 510 // First student's: ID
.short 95,96
// Exam1
and Exam2
n1: .long 725
.short 96,82
n2: .long 233
.short 94,99
n3: .long 101
.short 95,86
n4: .long -1 // sentinel
.short 0,0 // NA
// ID2Exam1: Return Exam1 score for a given student
// Input: R0 has the ID of student whose Exam1 score is desired
// Output: R0 has the Exam1 score of the student if found
// if the student does not exist then R0 has 0
ID2Exam1: // R0 is the ID
LDR R1,=List // pointer
LDR R3,=-1 // sentinel
look: LDR R2,[R1,#0] // ID
CMP R2,R3
BEQ fail // end?
CMP R2,R0
BEQ yes // found
ADDS R1,R1,#8 // next
B look
fail: MOVS R0,#0 // fail
B done
yes: LDRH R0,[R1,#4] // Exam1
done: BX LR
1.11. Lab 1. Introduction to Cortex M Assembly
Lab 1. Introduction to Cortex M Assembly

Embedded
Systems - Shape the World by Jonathan Valvano and Ramesh Yerraballi is
licensed under a Creative
Commons
Attribution-NonCommercial-NoDerivatives 4.0 International License.
Based on a work at http://users.ece.utexas.edu/~valvano/mspm0/